Netty与Zero Copy
问题
- 零拷贝是什么,Netty 的零拷贝是什么?
- 零拷贝有什么优势?
背景
首先要清楚,零拷贝是什么。
OS 的 Zero Copy
在操作系统下,当我们在进行网络读(read)写(send)的时候,通常
1 | File.read(fileDesc, buf, len); |
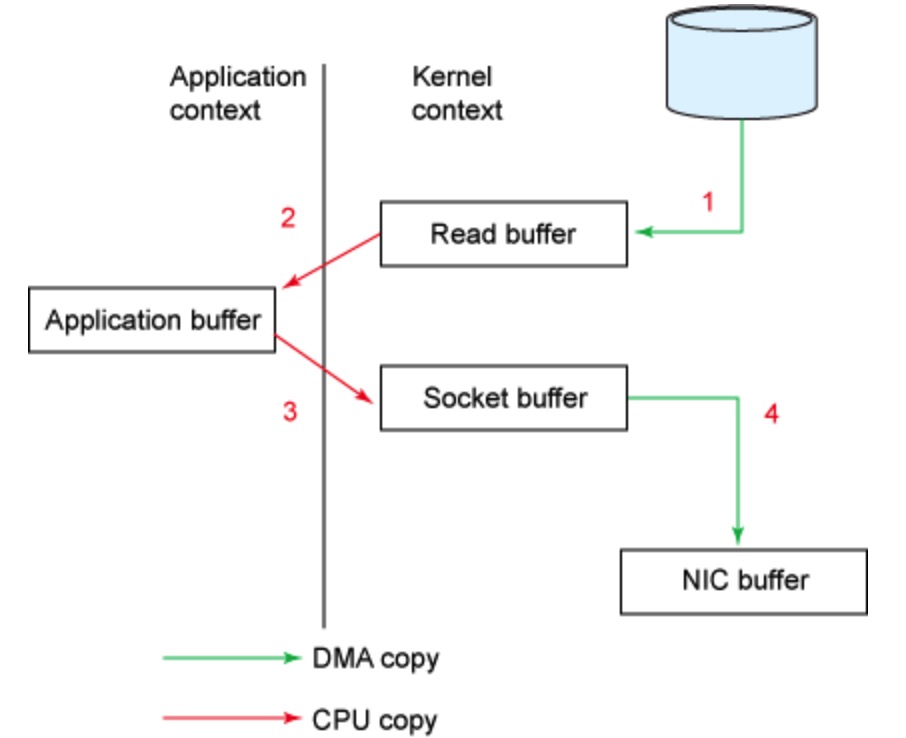
- read 导致调用从 用户态 转移到 内核态,会先检查文件内容是否存在于内核缓冲区,若存在则将内容 copy 到用户空间中,若不存在则会操作 DMA(Direct Memory Access) 从磁盘中读取 copy 到内核缓冲区[1], 在进行上述 copy 到用户控件的操作[2]. 此处可能存在 1-2 次 copy 操作,2 次用户态与内核态的上下文切换。这里可能因为文件内容过大导致内核缓冲区一直无法启用。
- send 再切换 用户态 到 内核态,将内容 copy 到 socket 缓冲区中[1],最后 socket 将缓冲区的内容发送(copy)到协议引擎[2]. 此处存在 2 次 copy 操作,1 次用户态与内核态的上下文切换。
下图是其 copy
下图是其上下文切换
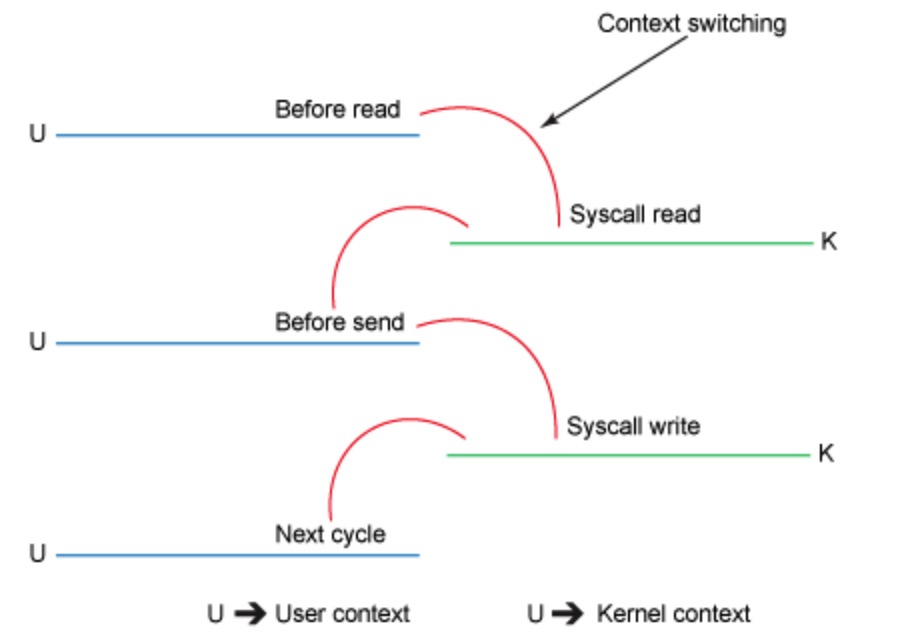
如上图,我们可以看出,其实从缓冲区 copy 到用户空间这两次 copy 及用户内核态直接的切换是完全可以避免的。这时候就需要使用到 zero copy 了。
在 Java 中,zero copy 通常是利用 FileChannel.transferTo 来实现。下面是其函数签名:
1 |
|
transferTo() 方法将数据从文件通道传输到了给定的可写字节通道。在内部,它依赖底层操作系统对零拷贝的支持;在 UNIX 和各种 Linux 系统中,此调用被传递到 sendfile() 系统调用中。
我们相较于之前的过程有什么改进呢?
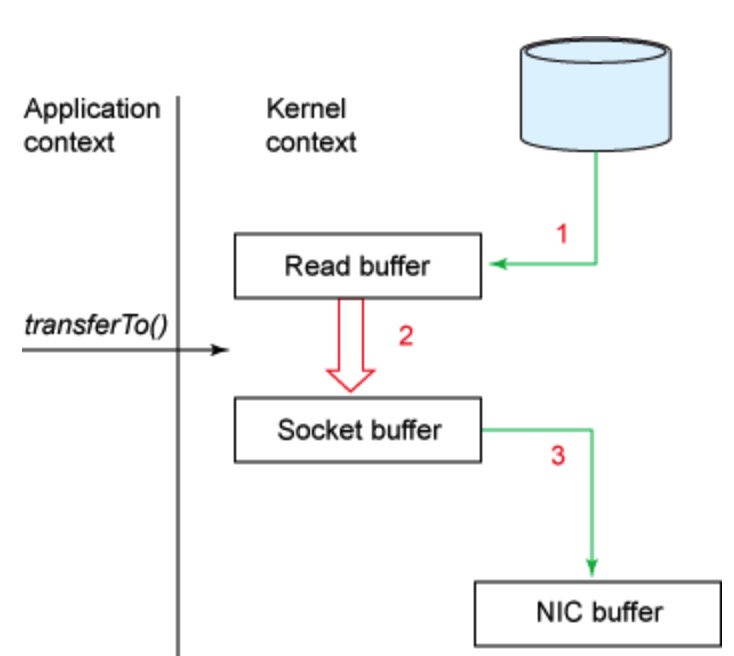
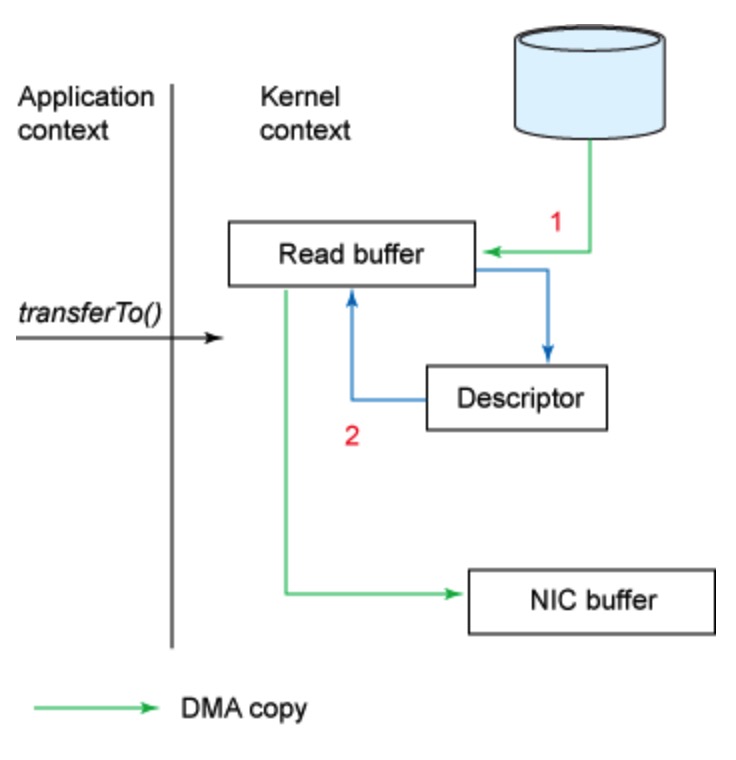
下图是 transferTo 的 copy 流程
下图是 transferTo 的上下文切换
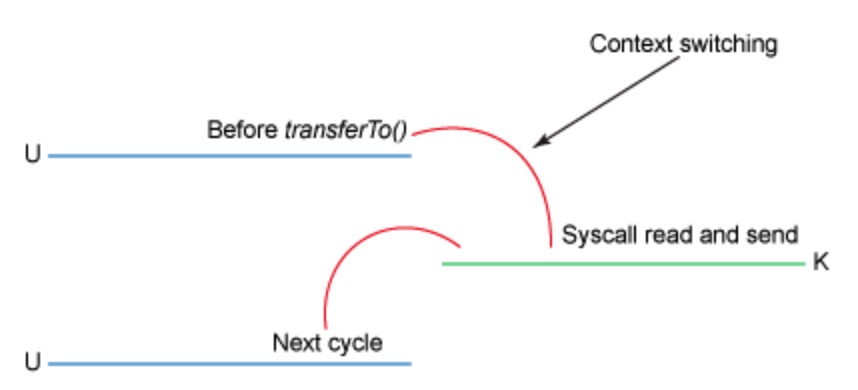
改进的地方:我们将上下文切换的次数从 4 -> 2次,将数据复制的次数从 4 -> 3 次(其中只有一次涉及到了 CPU)。但是这个代码尚未达到我们的零拷贝要求。如果底层网络接口卡支持收集操作的话,那么我们就可以进一步减少内核的数据复制。在 Linux 内核 2.4 及后期版本中,套接字缓冲区描述符就做了相应调整,以满足该需求。这种方法不仅可以减少多个上下文切换,还可以消除需要涉及 CPU 的重复的数据拷贝。对于用户方面,用法还是一样的,但是内部操作已经发生了改变:
- transferTo() 方法引发 DMA 引擎将文件内容拷贝到内核缓冲区。
- 数据未被拷贝到套接字缓冲区。取而代之的是,只有包含关于数据的位置和长度的信息的描述符被追加到了套接字缓冲区。DMA 引擎直接把数据从内核缓冲区传输到协议引擎,从而消除了剩下的最后一次 CPU 拷贝。
下图是结合了 transferTo 及收集操作的数据拷贝
Netty 中的 Zero Copy
在 Netty 的世界中 Zero Copy 其实有两层含义。
- 文档中的 Transparent zero copy is achieved by built-in composite buffer type. 是指在 Java 之上(user space)允许 CompositeByteBuf 使用单个 ByteBuf 一样操作多个 ByteBuf 而不需要任何 copy,通过
slice方法可以讲单个 ByteBuf 拆分为多个 ByteBuf 操作,但是其本质为操作一个 copy。更多的是指代 Netty 中对于数据高效率操作方式. - 如果你所在的系统支持 zero copy,则可以使用 FileRegion 来写入 Channel, ChannelHandlerContrext, or ChannelPipeline.
Demo
1 | public void compositeDemo() { |
我们两者都看.
CompositeByteBuf 剖析
其入口在 Unpooled.wrappedBuffer(int maxNumComponents, ByteBuf... buffers) 里,这里也有一些逻辑
1 | public static ByteBuf wrappedBuffer(int maxNumComponents, ByteBuf... buffers) { |
创建 CompositeByteBuf
1 | CompositeByteBuf(ByteBufAllocator alloc, boolean direct, int maxNumComponents, |
其参数含义:
- alloc: ByteBuf 分配
- direct: 是否是 DirectByteBuf
- maxNumComponents: 最多能组合 ByteBuf
- buffers:组合的 ByteBuf
- offset: ByteBuf 在总 ByteBuf 组合中的偏移值
整体逻辑
- 本质并没有创建一个整体的 ByteBuf,而是通过组合模式管理多个 ByteBuf,使用 Component 来包装每个 ByteBuf(
addComponents0) - Component 中存储的 ByteBuf 在总 ByteBuf 数组中的 offset 范围(
new Component) - read / write 需要先获取到具体的 Component(
getXXX/_setXXX/setXXX)再操作,获取逻辑:- 记录最近访问的 Component,优先检测
- 二分查找
Slice 剖析
这里入口在 ByteBuf.slice() 最后指向创建了 UnpooledSlicedByteBuf extends AbstractUnpooledSlicedByteBuf 类,其主要逻辑也是依托于 UnpooledSlicedByteBuf 实现。
主要逻辑
- 使用 adjustment 字段记录其分隔点,这里若原本就是
AbstractUnpooledSlicedByteBuf这需要叠加 adjustment - 重写
getXXX/_setXXX/setXXX等设计 index 方法
FileRegion 剖析
Demo
io.netty.example.file.FileServerHandler.channelRead0 实例
1 | public void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception { |
这里可以看出当 SSL 没有开启时可以使用 DefaultFileRegion,其是 FileRegion 的默认实现,内部封装了 FileChannel.transferTo 的方法,关于这个方法,上文已经介绍过了。
尝试回答
- 零拷贝一般大众所知是 Linux 中一种用于减少在文件(网络)读写过程中用户态与内核态互相切换,内核态数据需要 copy 到用户态的优化手段。在 Java 的中是以
FileChannel.transferTo来体现。 - Netty 的零拷贝分为两种。一种是使用 FileReigon 封装了
FileChannel.transferTo操作使得网络读写性能得到优化;另一种是使用 CompositeByteBuf 使用单个 ByteBuf 一样操作多个 ByteBuf 而不需要任何 copy,通过slice方法可以讲单个 ByteBuf 拆分为多个 ByteBuf 操作,但是其本质为操作一个 copy。更多的是指代 Netty 中对于数据高效率操作方式。与内核态用户态切换无关。 - Netty 对于 ByteBuf 的零拷贝让多种数据组合更加方便。零拷贝最多能减少两次无意义的 copy 操作且大幅减少内核态与用户态的上下文切换。
参考文档
通过零拷贝实现有效数据传输
Is Netty’s Zero Copy different from OS level Zero Copy?
对于 Netty ByteBuf 的零拷贝(Zero Copy) 的理解
Netty 之 Zero-copy 的实现(上)
Netty 之 Zero-copy 的实现(下)