从Producer到日志落盘
文章简介
- [正常]叙述 Kafka 从 Producer 发送消息到 Server 日志落盘全过程
- [提升]详解 Kafka 日志格式,并通过 Java / Rust 两类解析方式
- [深入]Rust-Kafka-Client Producer 到 Kafka Server
- 需要说明的是这篇文章的局限性
- 仅介绍两个 topic 各有两个 partition 为基础进行介绍,会调用
flush强行将消息刷新进入 topic 内。发送消息每个 partition 各 5 条 - 不涉及鉴权部分
- 不涉及事务消息及有序消息部分
- Kafka 版本 3.1.0,如无必要不会涉及老版本的历史包袱说明
- 流程图中只记录关键路径,关键信息,部分细节信息可能需要细看代码才行,但是不妨碍原理理解
- 这其中会涉及到
Replica跟Network的部分知识,但是在这篇文章中只会涉及到比较浅显的部分,我们默认网络层和主副本是对我们透明的,对其中细节及设计部分我们会在另外的文章中讲解。
- 仅介绍两个 topic 各有两个 partition 为基础进行介绍,会调用
请求到落盘
Producer 流程
示例
1 | ./kafka-topics --bootstrap-server localhost:9092 -create --topic dove_1 --partitions 2 --replication-factor 1 |
1 | public class KafkaProducerEx { |
产物
1 | ➜ dove_1-0 ls |
流程说明
KafkaProducer 发送消息实际上看只分为两个线程进行
- Main 线程,及由
KafkaProducer线程发起的,最终 Record 会经过拦截器、序列化到RecordAccumulator中并缓存称为 ProducerBatch 保存。 - Sender 线程,持续运行,主要是将
RecordAccumulator攒批的消息取出,构建 Request(Header + Body) (通过网络处理层)发送到 Server 端
流程说明
KafkaProducer 发送消息实际上看只分为两个线程进行
- Main 线程,及由 KafkaProducer 线程发起的,最终 Record 会经过拦截器、序列化到 RecordAccumulator 中并缓存称为 ProducerBatch 保存。
- Sender 线程,持续运行,主要是将 RecordAccumulator 攒批的消息取出,构建 Request(Header + Body) (通过网络处理层)发送到 Server 端
主线程
攒批
ProducerBatch攒批是由 KafkaProducer 用户的 send 方法发起,然后由 RecordAccumulator 生成 ProducerBatch 结束的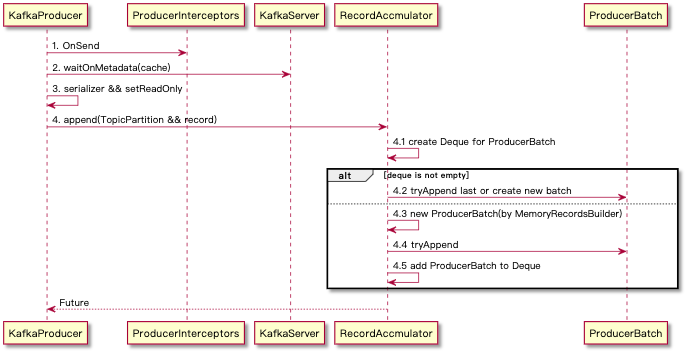
- 这里值得关注的细节
- KafkaProducer 的 send 实际并没有同步的实现方式
- RecordAccumulator 的缓存是通过 CopyOnWriteMap ,其中 Key 是以 TopicPartition 的维度进行组织的,其中的 Value 是一个 ArrayDeque
以保证有序。RecordAccumulator 缓存条件在 Sender 线程中有描述
构建字节码
由攒批的 4.4 tryAppend 中是构建 Record 字节码的流程,整体流程如下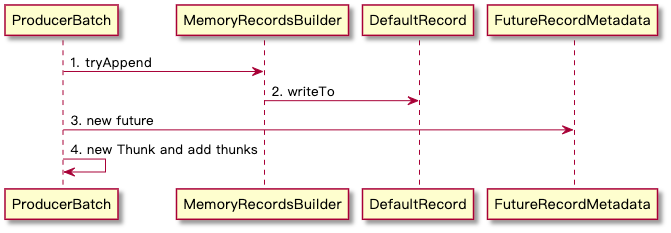
- 这里有部分细节需要注意
- append 中实际 MemoryRecordsBuilder 还负责使用 nextSequentialOffset 生成 Batch 中的相对 offset ,生成方式是 lastOffset == null ? baseOffset : lastOffset + 1,这其中 baseOffset 初始化是在 RecordAccumulator 中创建是 0,而 lastOffset 的值在 append 方法成功写入的最后会更新为当前 offset 值(recordWritten)
- append 的时候会传递一个 timestamp 值,这个值是由用户传递或者是自动生成,生成时间是 send 方法调用时间
- 最终构成的 record 格式见下文日志格式详解
flush 流程
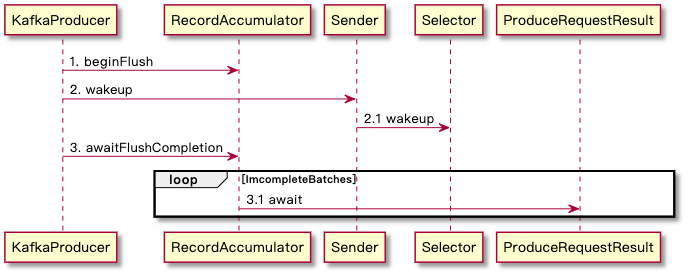
本质是让缓存 ready 与让 sender 线程阻塞结束
这里需要先介绍 flush.wakeup 机制:本质是调用 NIO Selector.wakeup ,即往管道中写入一个字节使得 Selector.poll 能获得数据这样就不再阻塞立即返回,驱动 Sender 线程运行
Sender 线程运行流程
整体流程
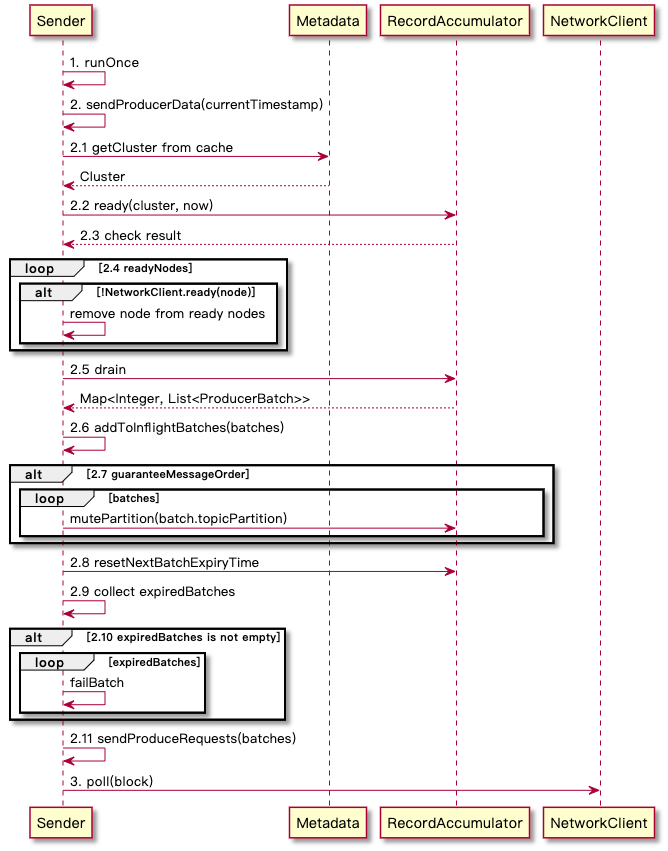
细节说明:
- 2.2 中 RecordAccumulator.ready 中详细叙述了哪个 nodeId 算是 ready 了,需要符合以下条件(且关系):
- 至少 node 中有一个 partition 没有处于 backingoff 的状态(batch.attempts() > 0 && waitedTimeMs < retryBackoffMs 即需要重试并且重试等待时间尚未达到)
- node 中的 partition 没有被其他写入操作持有(isMute,会发生在保序消息发送上)
- 满足以下任意条件
- 缓冲队列满了(deque.size > 1|| batch.full())即 partition 等待 batch 数量超过 1 个或者 Producer 被关闭/ 消息大小超过配置大小,这个配置简单可以理解成 _BATCH_SIZE_CONFIG_,如果单个消息超过了该配置情况会经过 AbstractRecords.estimateSizeInBytesUpperBound 计算得到)
- 等待时间超过 ProducerConfig.LINGER_MS_CONFIG 了
- 没有空闲内存(Record 的内存是提前分配的)
- 触发了 flush 操作(RecordAccumulator.beginFlush())
- RecordAccumulator 被 closed
- 对于 2.2 得到的 unknownTopic 的处理:更新元数据
- 2.11 sendProduceRequest 详见下面发送消息详情,这里的 batches 其结构是 Map<NodeId, List
,其中 NodeId 是 Integer 格式,提供给 Server 端找到具体存储节点的标识,这里在 Server 流程中也会详解路由流程
sendProducerRequest
通过给到的 List
- 主体流程
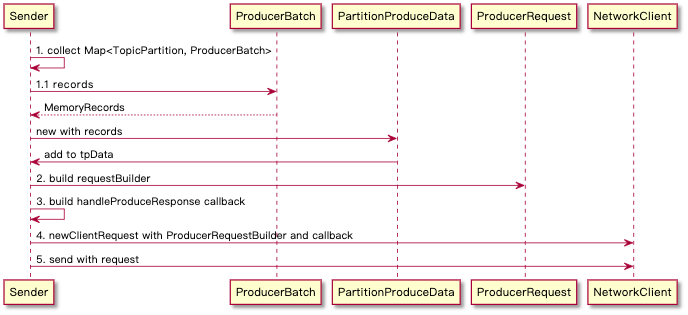
第一步生成 MemoryRecords 实际就是 ProducerRecord 生成 Buffer 的步骤,也是组成 ProducerRequest 重要一部分,这个在下文日志格式中会细说。
第三步 callback 是等待 Server 返回响应之后调用的,实际 Kafka Client 的交互都依赖于 callback 模式,等待 NetworkClient 调用,这个机制后续会单独出文细说。
callback-返回响应
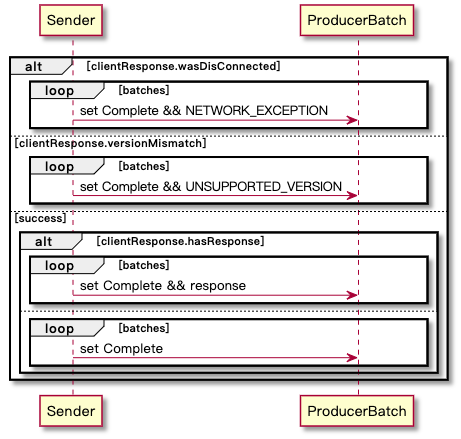
callback-资源回收
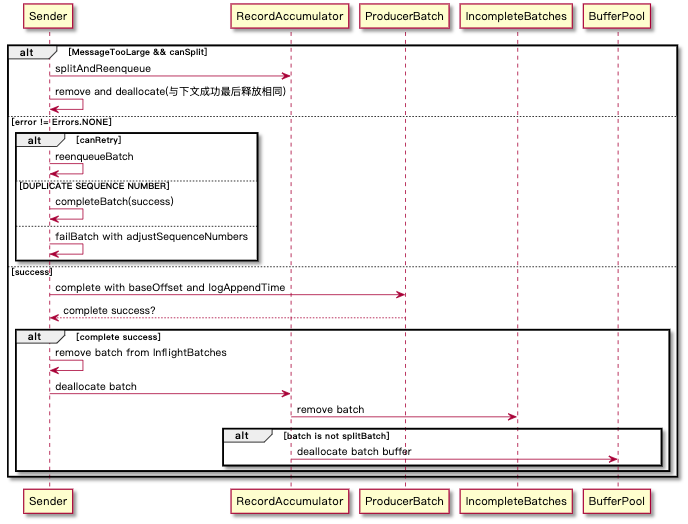
NetworkClient.send: 发送网络请求
InFlightBatches 机制,缓存了发送出去但还没接收到响应的请求,存储格式是 Map<NodeId, Deque<Request>> 。能用来干啥?
- 通过
max.in.flight.requests.per.connector限制每个连接最多缓存的未响应请求 - 较多的管理方法,可以用于请求是否完成(
handleCompletedSends)、获取过期请求(handleTimedOutRequests)
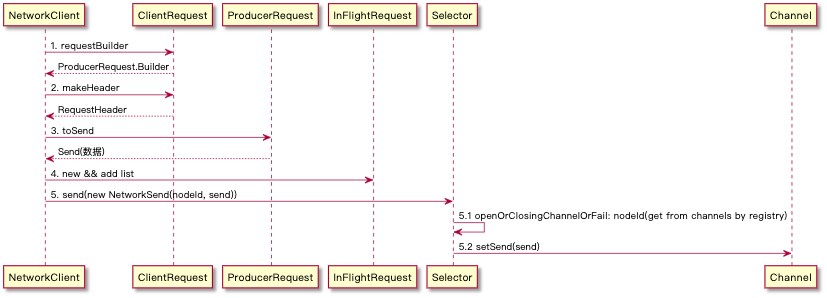
toSend
生成发送到 Server 中的数据,这里会通过 ProducerRequestData 递归式的构建 buffer,其中每份 Partition 的 Records 会组合成一个 buffer,最终成型的时候会通过 TransferableChannel.write(ByteBuffer[] srcs) 写入到网络层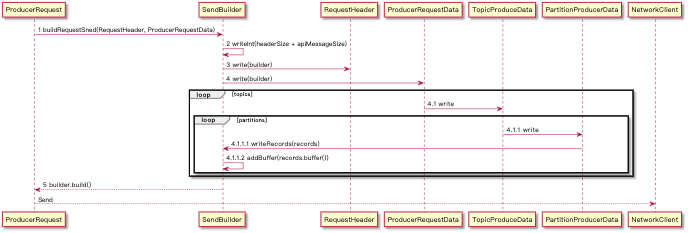
其中 2、3、4 步骤是构成数据的关键步骤,2/3 其实相对都简单,可以参考下文的消息格式得出。而 4 是我们 Records 发送的数据,同时由于一次发送是以 NodeId 为维度来发送的,所以可能一次会有多 Topic 及多 Partition 的数据,而他们的组织又是一个很好的亮点了,图中只是简单描述了其组织形式,即每个 partition 的数据会单独作为一个 buffer 加入最终要发送的 buffers 段中,具体可以参考下文日志格式详解。
NetworkClient.poll() :等待网络阻塞,处理响应并调用 callback 方法,可以说是关键方法了。

Server 流程
Request 在 Server 的处理步骤是这样的(简单叙述,后续网络协议详解)
- 根据
MsgSize来确定收到网络请求为完整的包,并记录数据(参考Selector#attemptRead中的bytesReceived = channel.read()对于网络请求的读取操作),读取之后后续分割为 Header + RequestBody 两部分 RequestHeader在SocketServer#parseRequestHeader中解析得到apiKey和apiVersion两部分- 根据
apiKey跟apiVersion解析 RequestBody 部分(RequestContext#parseRequest),最终落地到具体ProduceRequest.parse中
当 Selector 通过 KafkaChannel 将 Send 发出的时候会统一被 Server 的 KafkaRequestHandler(在 core 中的 kafka.server package 下) 处理。
随后在 KafkaApis.handle 中鉴定出来是 ApiKeys.PRODUCE 的消息,交由 KafkaApis.handleProduceRequest 方法处理, ApiKey 的指定是在 ProduceRequest 的构造器中就 set 了。如果这段描述没有问题的话我们的流程解析就从 KafkaApis.handleProduceRequest 开始了,与上文一样,会忽略细节,关注主要的数据处理流程。
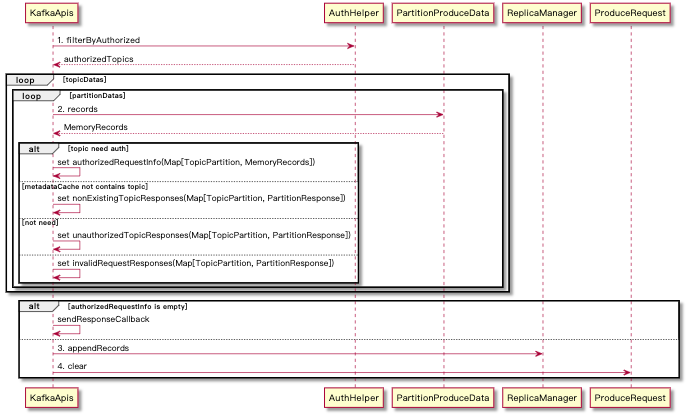
写消息大流程 appendRecords。
负责将消息以 TopicPartition 的维度将一个 partition 的 records 写入到文件中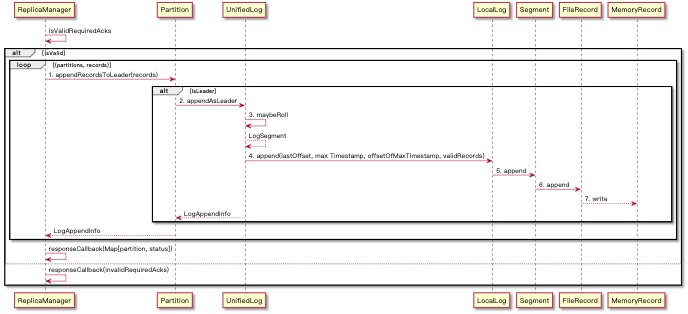
- 写入日志涉及到多个组件
ReplicaManager: 以 Replica 为单位(分配在 Broken (机器上) )来管理 Kafka Log,主要由:Scheduler: 来管理以下调度任务highwatermark-checkpoint: HighWatermark(HW) 是表明已备份的日志位点,这个定时任务会定时将 HW 刷新到 checkpoint 文件中isr-expiration: ISR(**In-sync Replicas**) 是确定哪些副本是与 Leader 同步的,该任务是管理 ISR 中 partition 到期之后更新 ISR 列表shutdown-idle-replica-alter-log-dirs-thread: 定时关闭空闲的 ReplicaAlterDirThread 线程,ReplicaAlterDirThread 是用来同步更新的 Replica 来替代当前 Replica 的 partitionMap 的,但是如果 partitionMap 是空的话它并不会自动关闭,所以就需要改定时任务。
LogManager: 统一管理日志操作入口
Partition: 负责单个 Partition 操作,是线程安全的。这里是作为 Leader 响应 append 请求并维护 HWUnifiedLog: 提供 Local 和 Tiered Log (Kafka 云端存储实现,目前看只有在 Confluent Platform 实现,在源码中没看到具体实现) Segment 的统一视图LocalLog:维护了 LogSegment 的 List,每一个 LogSegment 均携带一个独有的base offset, 用于 append-only Log 操作。同时基于配置项与当前活跃的 Segment 的创建时间间隔与存储容量决定是否创建新的 LogSegmentLogSegment: 基本可以表示日志实体了,代表 Broken 中某些文件(日志文件(FileRecords)、offset 索引文件(OffsetIndex)、timestamp 索引文件(TimeIndex)),其操作也是对于该文件的操作。FileRecord: 实际的日志文件实体,其中包含FileChannel的 NIO 接口用于 IO 操作MemoryRecord: 包含 Producer 传递上来的 Record Bytes,使用FileChannel写入到文件中
- 在
UnifiedLog#analyzeAndValidateRecords中通过DefaultRecordBatch会解析部分 record 的 header 信息来构成LogAppendInfo在后续使用,比如 lastOffset 等信息是构成 index 文件内容的关键要素。 - Segment 的组织方式
- 在
UnifiedLog#maybeRoll方法中如果满足以下条件可能会生成新的LogSegment,需要注意的是这个是一个同步(以UnifiedLog的维度阻塞)方法:LogSegmentis full:size > rollParams.maxSegmentBytes - rollParams.messagesSizeLogSegment中的第一条消息 timestamp 距离现在已经超过配置的 maxTime:timeWaitedForRoll(rollParams.now, rollParams.maxTimestampInMessages) > rollParams.maxSegmentMs - rollJitterMs- index is full:
offsetIndex.isFull || timeIndex.isFull
- Roll 这个操作是怎么操作的呢?
- 首先获取
rollOffset作为新生成的LogSegment的 base offset,如果获取失败则采用maxOffsetInMessages - Integer.MAX_VALUE作为一个启发式的 base offset 的值,这样它会小于真实 first offset(因为历史原因在之前版本中 first offset 的获取是需要解压缩的)
- 首先获取
- 在
1 | val maxOffsetInMessages = appendInfo.lastOffset |
- `UnifiedLog#roll` 方法直接调用了 `LocalLog#roll` 方法新增了 `LogSegment`,同时还启动了 `flush-log` 的调度任务清理过期日志、更新 HW、更新 `ProducerStateManager` 快照
- `LocalLog#roll` 操作
- 生成三个文件 `offsetIdxIndex` , `timeIdxFile` , `txnIdxFile`
- 将当前活跃的 `segment` 置为不可写状态 `onBecomeInactiveSegment`(通过添加一个 `largest time index entry` 到日志和索引文件最后一行并将当前文件保留字节之后的内容均使用 `truncateTo` 的方式截取了以避免文件空洞)
- 通过 `LogSegment#open` 生成新的 Segment 并加入到 `LogSegments` 中,由于 `LocalLog#activeSegment` 是获取 `LogSegments` 的最后一个 segment 的,自然也就更新了
- 更新 `LogEndOffset`
- 在
LocalLog以LogSegments的数据结构管理,以ConcurrentNavigableMap[Long, LogSegment]其中 key 是LogSegment的 base offset。提供了增删查改的简单方法。 - FileChannel 写文件方式可以参考:https://zhuanlan.zhihu.com/p/27650977
日志文件解析
我们通过上面的分析大概得出两个方向来分析 ProducerRequest ,一个是 Producer 写的部分也就是涉及 MemoryRecordsBuilder 到 NetworkClient.toSend 部分;第二个是从 Server 解析的部分,从 Selector#attemptRead 开始到 RequestHeader 再到 ProducerRequest#parse 来看。不管是通过哪个部分都可以得到以下的结构(不过涉及到 key value 的部分还是需要在 **MemoryRecordsBuilder#appendDefaultRecord** 中寻找答案的,Server 并不会解析内容,自会存储字节)。分为三个部分。
- Request 消息体
- MsgSize:表示请求体大小
- RequestHeader:只包含两个字段
apiKey: 标记请求类型apiVersion: 标记客户端版本
- ProducerRequestData
length(transactionalId):UnsignedVarint() - 1- if length > 0 |
transactionalId:String(length) ack:shorttimeoutMs:int- Topics[Array] |
arrayLength:UnsignedVarint() - 1| for 循环length(name):UnsignedVarint() - 1- if length > 0 | name:
String(length) - Partitions[Array] |
arrayLength:UnsignedVarint() - 1| for 循环index:intlength(records):UnsignedVarint() - 1- if length > 0 |
records:MemoryRecords(bytes[length]) _unknownTaggedFields[Map]…
_unknownTaggedFields[Map]…
_unknownTaggedFields[Map] |_numTaggedFields:UnsignedVarint()| for 循环- _tag:
UnsignedVarint() - _size:
UnsignedVarint() List<RawTaggedField>: bytes[size]
- _tag:
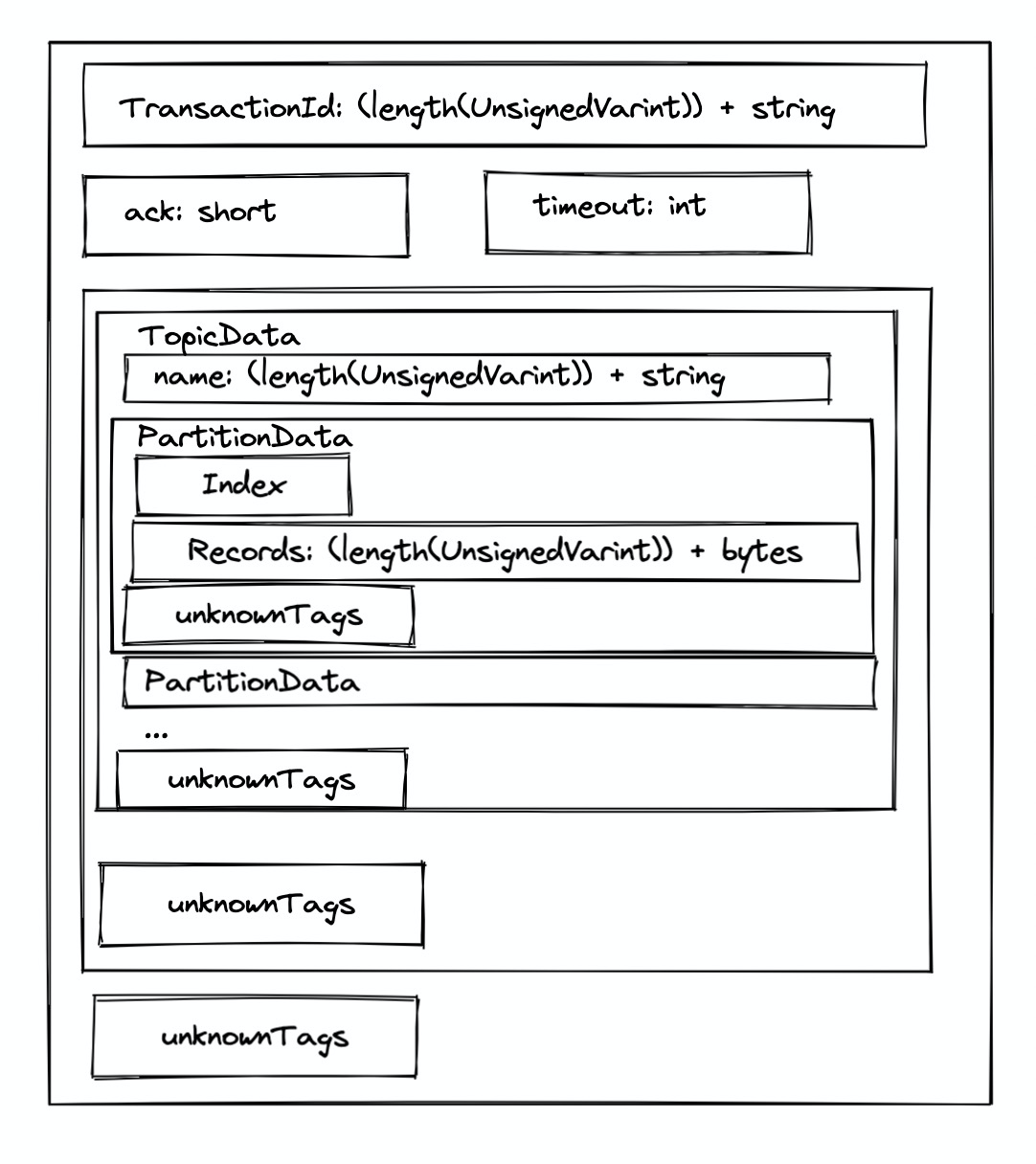
Records
- 由
ProduceRecord转换到 bytes 是在KafkaProdcer#doSend中经过序列化借由部分中间传递到MemoryRecordsBuilder#appendDefaultRecord成型- timestamp: send 的时间
- offset:
MemoryRecordsBuild#lastOffset相对索引
- BatchHeader: 在消息构建的时候需要注意的是,由
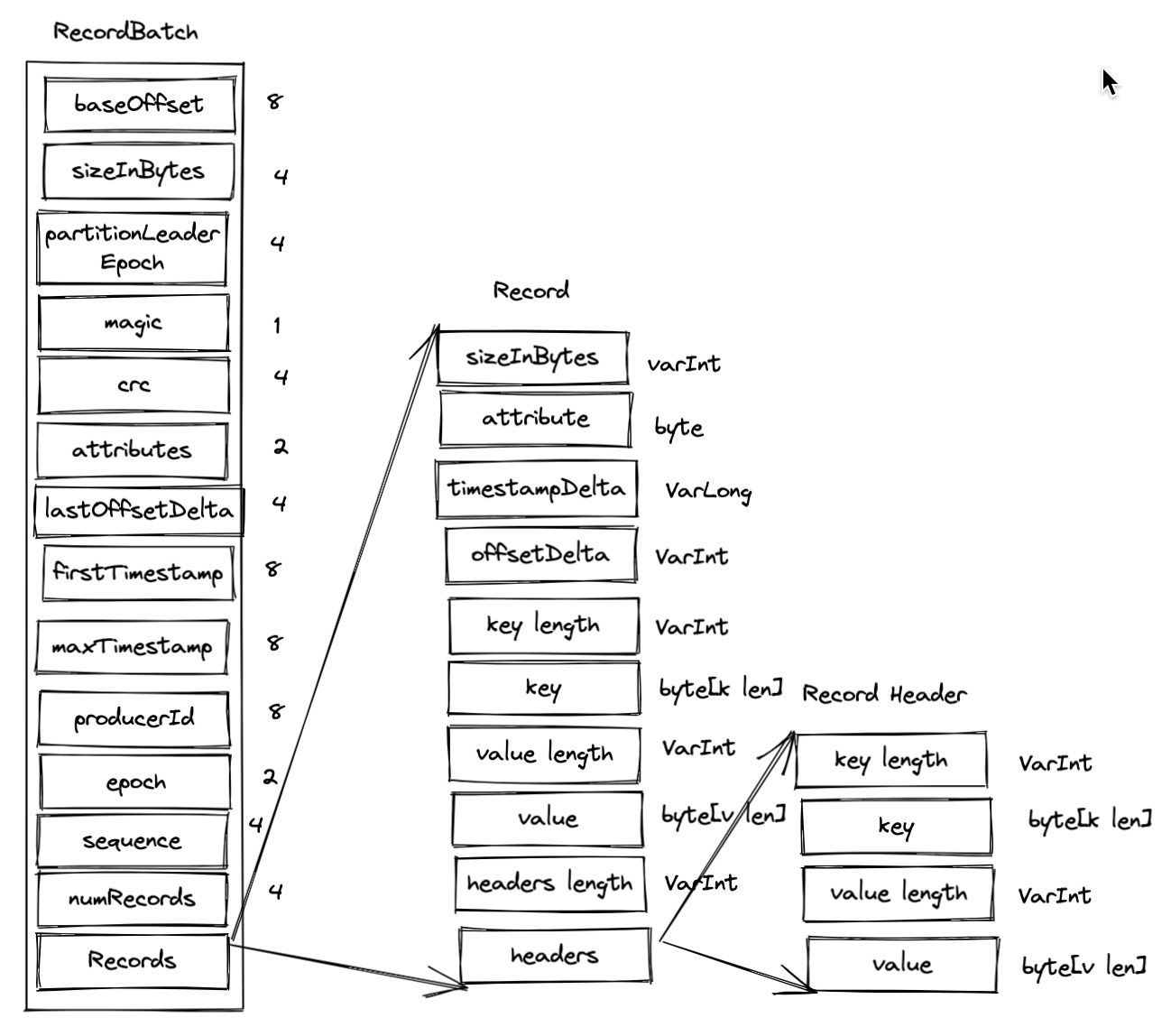
ProducerBatch#records()→MemoryRecordsBuilder#build→MemoryRecordsBuilder#close→MemoryRecordsBuilder#writeDefaultBatchHeader流程中会先将统一 header 放入 bytes 中,然后再将 records 放入 bytes 中。所以整体结构是这样的。
这里面大量采用了 VarInt/Long 来在小数字或者负数的情况下节省字节,这个也是 protobuf 常用手段,可以参考这篇文章:https://segmentfault.com/a/1190000020500985 对于编码有详细的介绍。
- RecordBatch 字段介绍
- baseOffset: 基准 offset,Producer 始终为 0,Customer 消费的时候以
LogSegment的 baseOffset 为准 - sizeInBytes: 计算从 partition leader epoch 字段开始到末尾的长度
- partitionLeaderEpoch: 分区 leader 版本号(更新次数)
- magic: 表示消息格式版本
- attributes: 消息属性,低三位表示压缩格式(NONE: 0, GZIP: 1, SNAPPY: 2 LZ4: 3,其余位保留);第四位表示时间戳类型();第五位表示次 RecordBatch 是否处于事务中(0 表示非事务,1 表示事务);第六位表示是否是控制消息(0表示非,1 表示是。控制消息用来支持事务功能);第八位表示该消息是否被删除(Kafka 2.5.0 在 KIP-534 加入的特性)。
- firstTimestamp: 首个消息的 timestamp
- maxTimestamp: RecordBatch 最大的时间错,一般就是最后一个,用来保证消息组装的正确性
- lastOffsetDelta: RecordBatch 中最优一个 Record 的 offset 与 first offset 的差值,主要被 broker 用来确保 RecordBatch 中 Record 组装的正确性。
- producerId: PID,用来支持幂等和事务
- epoch: 和 PID 相同,用来支持幂等和事务
- sequence: 和 PID 相同,用来支持幂等和事务
- numRecords: records 的个数
- crc: crc32 校验值,范围覆盖了 attributes 到 records
- records: 消息主体
- baseOffset: 基准 offset,Producer 始终为 0,Customer 消费的时候以
- Record 介绍
- sizeInBytes: 消息总长度
- attribute: 启用,保留值
- timestampDelta: 时间戳增量,相对于外部 firstTimestamp
- offsetDelta: offset 增值,相对于 baseOffset
- key length & key: key 值,如果是空 value = -1
- value length & value: value 值
- headers length & header: headers
- RecordHeader 介绍
索引文件与日志文件映射关系
Kafka 的索引文件是以稀疏索引(sparse index)的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引项。每当写入一定量(由 broker 参数
log.index.interval.bytes决定,默认值为 4096)的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间错索引项。1
2
3
4
5if (bytesSinceLastIndexEntry > indexIntervalBytes) {
offsetIndex.append(largestOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
bytesSinceLastIndexEntry = 0
}offsetIndex 与 log 文件代表的是 offset (RecordBatch 最大的 offset 的相对偏移量)与对应消息的 log 物理位置映射关系(largestOffset → physicalPosition)
timeIndex 是当前日志分段的最大时间戳和时间戳锁对应的消息相对偏移量。即如果此次的消息时间戳小于之前追加的时间戳则不予追加,这实际是一个保证 customer 通过 timestamp 来消费的话能稳定消费到在这个 timestamp 后续追加的消息的手段,假设 Producer 出现时间跳动则 customer 在消费的时候也可以跳过之前的消息消费到最新的消息。