【论文阅读】FlumeJava_ Easy, Efficient Data-Parallel Pipelines
FlumeJava: Easy, Efficient Data-Parallel Pipelines
摘要
MapReduce 及类似系统极大地简化了编写数据并行代码的任务。然而,许多现实世界的计算需要一系列的 MapReduce 操作,编程和管理这些流水线可能很困难。我们介绍了 FlumeJava,一个Java库,它简化了开发、测试和运行高效数据并行流水线的过程。FlumeJava 库核心是一些代表不可变并行集合的类,每个类都支持一些操作,用于并行处理这些集合。并行集合及其操作提供了一个简单的、高层次的、统一的抽象,覆盖了不同的数据表示和执行策略。为了使并行操作能够高效运行,FlumeJava 推迟了它们的评估,而是在内部构建了一个执行计划数据流图。当最终需要并行操作的结果时,FlumeJava首先优化执行计划,然后在适当的底层原语(例如,MapReduces)上执行优化后的操作。并行数据和计算的高层抽象、延迟评估和优化以及高效的并行原语的结合,产生了一个易于使用的系统,其效率接近手动优化的流水线。FlumeJava目前正被谷歌内部数百名流水线开发者积极使用。
FlumeJava 是 Google 内部开发的一个库,专门用于简化大规模数据处理工作。它没有被开源。不过,FlumeJava 的概念和设计哲学影响了许多开源项目。
相似的开源实现最为出名的 Apache Beam:这是一个更广为人知的、由 Google 贡献给 Apache 软件基金会的开源项目。Apache Beam 提供了一种统一的编程模型,用于定义和执行数据处理工作流。这个项目的目标是允许你编写一次数据处理代码,然后在多个执行引擎(如 Apache Flink、Apache Spark 和 Google Cloud Dataflow)上运行。
介绍
构建程序以并行处理大量数据可能非常困难。MapReduce 极大地简化了数据并行计算的任务。它为用户提供了一个简单的抽象,让用户理解他们的计算应该如何进行,并且它管理了许多困难的底层任务,比如在许多机器上分发和协调并行工作,以及健壮地处理机器、网络和数据的故障。MapReduce 在实际中被许多开发者非常成功地使用。MapReduce 在这一领域的成功激发了一系列相关系统的开发,包括Hadoop、LINQ/Dryad 和 Pig。
MapReduce 对于可以分解为 map 步骤、shuffle 步骤和 reduce 步骤的计算效果很好,但对于许多现实世界的计算,需要一系列 MapReduce 阶段的链条。这样的数据并行流水线需要额外的协调代码来连接各个独立的 MapReduce 阶段,并需要额外的工作来管理流水线阶段之间的中间结果的创建和后续删除。逻辑计算可能会被所有这些底层的协调细节所掩盖,使得新开发者很难理解计算过程。此外,流水线被划分成特定阶段的决定一旦“固化”到代码中,如果逻辑计算需要演化,后续便很难改变。
主要是解释逻辑推导与理解在 mapreduce 中的合理性,也可以提升可维护性
在本文中,我们介绍了FlumeJava,这是一个旨在支持数据并行流水线开发的新系统。FlumeJava是一个以几个表示并行集合的类为中心的Java库。并行集合支持一定数量的并行操作,这些操作组合起来实现数据并行计算。使用FlumeJava的抽象,整个流水线或甚至多个流水线可以在单个Java程序中实现;没有必要将逻辑计算分解成每个阶段的单独程序。
FlumeJava的并行集合抽象掉了数据表示的细节,包括数据是作为内存中的数据结构、一个或多个文件,还是作为外部存储服务(例如MySql数据库或Bigtable)来表示。类似地,FlumeJava的并行操作抽象掉了它们的实现策略,比如一个操作是作为本地顺序循环实现的,还是作为远程并行MapReduce调用实现的,或者(将来)作为数据库上的查询或作为流计算实现的。这些抽象使得整个流水线最初可以在小型的内存中测试数据上开发和测试,运行在单个进程中,并使用标准的Java IDE和调试器进行调试,然后在大型生产数据上完全不变地运行。它们还赋予了FlumeJava逻辑计算的适应性,因为新的数据存储机制和执行服务被开发出来。
为了实现良好的性能,FlumeJava内部使用延迟评估来实现并行操作。调用一个并行操作实际上并不立即执行该操作,而是仅仅在内部执行计划图结构中记录操作及其参数。一旦构建了整个计算的执行计划,FlumeJava会优化执行计划,例如将一系列的并行操作融合成少量的MapReduce操作。然后,FlumeJava运行优化后的执行计划。在运行执行计划时,FlumeJava选择用哪种策略来实现每个操作(例如,基于处理数据的大小选择本地顺序循环还是远程并行MapReduce)、将远程计算放置在它们操作的数据附近,并且并行执行独立操作。FlumeJava还管理计算中所需的任何中间文件的创建和清理。优化后的执行计划通常比具有相同逻辑结构的MapReduce流水线快几倍,并且接近于有经验的MapReduce程序员编写的手工优化的MapReduce链的性能,但需要的努力要少得多。FlumeJava程序也比手工优化的MapReduce链更易于理解和更改。
Flume 主要特点在于保留了逻辑的同时提供了类似优化器的能力(因为内部使用延迟评估来实现并行操作所以客观上为优化提供了条件),在优化之后的 Flume 流程会相较于未优化的流程有数倍的提升。
可维护与性能之间的平衡。
截至2010年3月,FlumeJava已在谷歌使用了将近一年的时间,在过去的一个月里有175位不同的用户,并且有许多流水线正在生产环境中运行。根据一些传闻,用户发现FlumeJava比MapReduce更容易使用。我们的主要贡献如下:
- 我们开发了一个基于一组可组合原语的Java库,这个库既具有表现力也很便利。
- 我们展示了这个API是如何自动转化成一个高效的执行计划的,使用了延迟评估和诸如融合之类的优化方法。
- 我们开发了一个运行时系统,用于执行优化后的计划,该系统能够自动选择本地执行还是并行执行,并管理运行流水线的许多底层细节。
- 我们通过基准测试证明了我们的系统能够高效地将逻辑计算转换为高效的程序。
- 我们的系统正被许多开发者积极使用,并且已经处理了数PB(petabytes)的数据。
本文的下一节将提供一些关于MapReduce的背景知识。第三节从用户的视角介绍FlumeJava库。第四节描述FlumeJava的优化器,第五节描述FlumeJava的执行器。第六节通过使用使用统计和基准性能结果来评估我们的工作。第七节将我们的工作与相关系统进行比较。第八节总结。
MapReduce 背景
FlumeJava建立在MapReduce引入的数据并行编程概念和抽象之上。一个MapReduce包括三个阶段:
- Map阶段:开始时,它从输入源读取一组值或键/值对,比如文本文件、二进制记录导向的文件、Bigtable或MySql数据库。大型数据集通常由多个,甚至数千个文件(称为分片)表示,多个文件分片可以作为单一逻辑输入源读取。Map阶段然后在每个元素上独立并行地调用用户定义的函数,即Mapper。对于每个输入元素,用户定义的函数会发出零个或多个键/值对,这些是Map阶段的输出。大多数MapReduce有一个(可能分片的)输入源和一个Mapper,但通常一个MapReduce可以有多个输入源和关联的Mapper。
- Shuffle阶段:接收Mappers发出的键/值对,并将所有具有相同键的键/值对分组在一起。然后它将每个不同的键和与该键相对应的所有值的流输出到下一个阶段。
- Reduce阶段:接收Shuffle阶段发出的按键分组的数据,并独立并行地在每个不同的键和值组上调用用户定义的函数,即Reducer。每次Reducer调用都会传递一个键和一个迭代器,迭代器遍历与该键关联的所有值,并发出零个或多个要与输入键关联的替代值。通常情况下,Reducer会对具有给定键的所有值执行某种形式的聚合操作。对于其他MapReduce,Reducer只是一个恒等函数。从所有Reducer调用中发出的键/值对随后被写入到输出接收器,例如一个分片的文件、Bigtable或数据库。
介绍了 MapReducer 的三个阶段 Map -> Shuffle -> Reduce
对于Reducer,如果它们首先使用一个关联的、可交换的操作组合具有给定键的所有值,则可以指定一个单独的用户定义的Combiner函数,在Map阶段期间执行与给定键关联的值的部分组合。每个Map工作节点将保留从Mapper发出的键/值对的缓存,并努力在发送到Shuffle阶段之前尽可能多地本地组合。Reducer通常会完成组合步骤,组合不同Map工作节点的值。
默认情况下,Shuffle阶段会将每个键和值组发送给一个确定性的但随机选择的Reduce工作节点机器;这个选择决定了哪个输出文件分片将保存该键的结果。或者,可以指定一个用户定义的Sharder函数,用于选择哪个Reduce工作节点机器应接收给定键的组。用户定义的Sharder可以用来帮助负载均衡。它也可以用来将输出键排序到Reduce“桶”中,第i个Reduce工作节点的所有键都排在第i+1个Reduce工作节点的所有键之前。由于每个Reduce工作节点按字典顺序处理键,这种Sharder可以用来产生排序输出。
在这三个阶段中,可以并行地使用许多物理机器。MapReduce自动处理选择合适的并行工作机器、分发程序以供运行、在三个阶段之间管理中间数据的临时存储和流动,以及同步各个阶段整体顺序的底层问题。MapReduce还自动应对机器、网络和软件的临时故障,这些故障在运行于数百台机器的分布式程序中可能是一个巨大且常见的挑战。
MapReduce的核心是用C++实现的,但存在允许从其他语言调用MapReduce的库。例如,MapReduce的Java版本是通过Java本地接口(JNI)在C++版本MapReduce之上实现的。
MapReduce提供了一个框架,将并行计算映射到其中。Map阶段支持尴尬并行(即非常容易并行化)的逐元素计算。Shuffle和Reduce阶段支持跨元素的计算,如聚合和分组。使用MapReduce编程的艺术主要涉及将逻辑并行计算映射到这些基本操作中。许多计算可以表示为一个MapReduce,但许多其他计算需要一系列或图形的MapReduces。随着逻辑计算的复杂度增长,将其映射到物理MapReduces序列的挑战也随之增加。像“统计出现次数”或“通过键连接表”这样的高级概念必须手动编译成更低级的MapReduce操作。此外,用户还承担了编写驱动程序以正确顺序调用MapReduces、管理创建和删除保存在MapReduces之间传递数据的中间文件以及处理MapReduces之间的故障的额外负担。
The FlumeJava Library
在这一节中,我们将展示FlumeJava库的接口,就像FlumeJava用户看到的那样。FlumeJava库旨在提供接近用户逻辑计算中发现的结构,并从不同输入输出存储格式的底层“物理”细节中抽象出来,以及将逻辑计算合适地分割成一个MapReduce图的过程。
Core Abstractions
FlumeJava库的核心类是PCollection,它是一个(可能非常巨大的)不可变的元素集合,这些元素的类型是T。一个PCollection可以有一个明确的顺序(称为序列),或者元素可以是无序的(称为集合)。因为限制较少,集合的生成和处理比序列更高效。一个PCollection可以通过一个内存中的Java Collection来创建。一个PCollection也可以通过读取各种可能的格式之一的文件来创建。例如,一个文本文件可以被读取为一个PCollection,一个二进制的面向记录的文件可以被读取为一个PCollection,前提是给出如何将每个二进制记录解码成一个类型为T的Java对象的规范。由多个文件分片表示的数据集可以作为一个单一的逻辑PCollection被读入。例如:
1 | PCollection<String> lines = readTextFileCollection("/gfs/data/shakes/hamlet.txt"); |
在这段代码中,recordsOf(…) 指定了一种特定的方式,用于将DocInfo实例编码为二进制记录。其他预定义的编码规范包括strings()用于UTF-8编码的文本,ints()用于32位整数的可变长度编码,以及pairsOf(e1,e2)用于根据组件的编码派生的成对编码。用户可以指定他们自己的自定义编码。
FlumeJava能够将这些分散的文件作为一个整体的逻辑PCollection来进行读取和处理,这样简化了对大型分布式数据集的操作
第二个核心类是PTable<K,V>,它代表着一个(可能非常巨大的)不可变的多值映射,拥有类型为K的键和类型为V的值。PTable<K,V>是PCollection<Pair<K,V>>的子类,实际上它就是一个无序的成对集合。有些FlumeJava操作只适用于成对的PCollection,在Java中我们选择定义一个子类来体现这种抽象;在另一种语言中,PTable<K,V>可能更适合被定义为PCollection<Pair<K,V>>的类型同义词。
操纵PCollection的主要方式是通过调用其数据并行操作。FlumeJava库只定义了少数几个基本的数据并行操作;其他操作都是基于这些基本操作实现的。核心数据并行基本操作是parallelDo(),它支持对输入PCollectionPCollection<S>。这个操作的主要参数是DoFn<T, S>,一个类似函数的对象,定义了如何将输入PCollectionPCollection<S>中出现的零个或多个值。它还接受一个指示,说明要作为结果产生的是哪种类型的PCollection或PTable。例如:
1 | PCollection<String> words = lines.parallelDo(new DoFn<String,String>() { |
在这段代码中,collectionOf(strings())指定parallelDo()操作应该产生一个无序的PCollection,其String元素应该使用UTF-8进行编码。其他选项包括sequenceOf(elemEncoding)用于有序的PCollections和tableOf(keyEncoding, valueEncoding)用于PTables。emitFn是一个回调函数,FlumeJava传递给用户的process(…)方法,它应该对每个应该添加到输出PCollection中的outElem调用emitFn.emit(outElem)。FlumeJava包含了DoFn的子类,例如MapFn和FilterFn,它们在特殊情况下提供了更简单的接口。还有一个版本的parallelDo()允许从输入PCollection的单次遍历中同时产生多个输出PCollection。
parallelDo() 可以用来实现MapReduce中的映射(map)和归约(reduce)环节。由于这些操作可能会在远程节点上并行分布执行,DoFn函数不应该访问封闭Java程序中的任何全局可变状态。理想情况下,它们应该是其输入的纯函数。DoFn对象维护局部实例变量状态也是允许的,但用户需要知道,可能会有多个DoFn副本同时运行,且它们之间没有共享状态。MapReduce也有同样的限制。
第二个基础函数**groupByKey()**,将类型为PTable<K,V>的多映射(可能有许多相同键的键/值对)转换为类型为PTable<K, Collection>的单映射,每个键都映射到一个无序的、简单的Java Collection,包含所有具有该键的值。例如,以下代码计算了一个表,将URL映射到链接到这些URL的文档的集合:
1 | PTable<URL,DocInfo> backlinks = docInfos.parallelDo(new DoFn<DocInfo, Pair<URL,DocInfo>>() { |
groupByKey()捕获了MapReduce中shuffle步骤的本质。它还有一个变体,允许为每个键的值集合指定一个排序顺序。
第三个原语,**combineValues()**,接受一个输入PTable<K, Collection
1 | PTable<String,Integer> wordsWithOnes = words.parallelDo(new DoFn<String, Pair<String,Integer>>() { |
combineValues()在语义上只是parallelDo()的一个特殊情况,但组合函数的关联性允许它通过结合MapReduce的combiner(作为每个mapper的一部分运行)和MapReduce的reducer(完成组合)来实现,这比在reducer中完成所有组合要更高效。
第四个原语**flatten()**,接受一个PCollection
一个管道通常以将最终结果PCollections写入外部存储的操作结束。例如:
1 | wordCounts.writeToRecordFileTable("/gfs/data/shakes/hamlet-counts.records"); |
因为PCollections是常规的Java对象,它们可以像其他Java对象一样被操作。特别是,它们可以作为参数传递给常规的Java方法,并且可以从这些方法中返回,它们还可以存储在其他Java数据结构中(尽管它们不能存储在其他PCollections中)。此外,常规的Java控制流构造可以用来定义涉及PCollections的计算,包括函数、条件语句和循环。例如:
1 | Collection<PCollection<T2>> pcs = new Collection<...>(); |
FlumeJava 提供了以下关键概念:
- PCollection: 表示一个并行的、分布式的数据集合,可以包含任何类型的元素,是 FlumeJava 处理数据的基本单位。
- PTable: 是一种特殊类型的 PCollection,用于表示键值对数据(类似于MapReduce中的中间结果)。
- parallelDo: 类似于 MapReduce 中的 map 和 reduce 操作,用于对 PCollection 中的元素进行转换和处理。它可以接受一个用户定义的函数,并对数据集中的每个元素应用这个函数。
- groupByKey: 一个操作,用于按键对 PTable 中的元素进行分组,将具有相同键的元素聚合到一起。它体现了 MapReduce 中 shuffle 步骤的本质,并支持变体来指定排序顺序。
- combineValues: 一个操作,接受一个 PTable<K, Collection
> 和一个关联组合函数,用于将每个键对应的值集合合并成单一的值。这优化了数据处理,类似于 MapReduce 中的 combiner 步骤。 - flatten: 一个操作,将多个 PCollection 对象合并成一个,它创建了一个视图,将多个集合逻辑上视为一个单一集合。
- 外部存储操作: FlumeJava 的管道通常以将最终结果写入到外部存储结束,比如文件系统或数据库。
FlumeJava 的设计目的是为了使得数据处理工作既高效又易于理解和维护,这些核心抽象概念在实现这一目标中起到了关键作用。通过这些抽象,FlumeJava 提供了一种更高层次的编程模式,隐藏了 MapReduce 编程模型中的许多复杂性,允许开发者专注于数据处理逻辑,而不是底层实现细节。
Derived Operations
FlumeJava库包括许多其他对PCollections进行操作的方法,但这些其他方法是派生操作,它们是根据这些原始操作实现的,并且与用户可能编写的帮助函数没有区别。例如,count()函数接受一个PCollection
1 | PTable<String,Integer> wordCounts = words.count(); |
FlumeJava库的另一个函数join(),实现了在共享相同键类型的两个或多个PTables之间的某种连接操作。当应用于一个多映射PTable<K, V1>和一个多映射PTable<K, V2>时,join()返回一个单映射PTable<K, Tuple2<Collection
- 对每个输入PTable<K, Vi>应用parallelDo(),将其转换为PTable<K, TaggedUnion2<V1,V2>>的通用格式。
- 使用flatten()合并表格。
- 对合并后的表格应用groupByKey(),产生一个PTable<K, Collection<TaggedUnion2<V1,V2>>>。
- 对键分组后的表格应用parallelDo(),将每个Collection<TaggedUnion2<V1,V2>>转换为一个Tuple2,包含一个Collection
和一个Collection 。
另一个有用的派生操作是top(),它接受一个比较函数和一个数量N,并返回其接收PCollection中根据比较函数确定的最大的N个元素。这个操作是在parallelDo()、groupByKey()和combineValues()之上实现的。
上面提到的将多个文件碎片作为单个PCollection读取的操作也是派生操作,使用flatten()和单文件读取原语实现。
主要介绍了一些构建在核心抽象之上的更高级别的数据处理操作。这些派生操作是基于PCollection和PTable的基本操作(如parallelDo()、groupByKey()、combineValues()和flatten())实现的,它们提供了更易用的接口,让开发者能够针对特定的数据处理场景编写更简洁的代码。派生操作在内部使用这些基本操作的组合来完成更复杂的任务,但对用户来说,它们看起来就像库中已经定义好的函数。
在这个章节中,讨论了如下几个派生操作的例子:
- join():用于在共享公共键类型的两个或多个PTables之间执行连接操作。它返回一个包含每个键和这个键在两个输入表中的所有值的集合的PTable。
- top():根据提供的比较函数返回PCollection中最大的N个元素。这对于找出数据集中的前N个最大或最小元素很有用。
- 读取多个文件碎片作为单个PCollection的操作:这种派生操作允许将来自多个分散数据源的数据作为一个逻辑集合处理。
上面内容强调了FlumeJava的能力,即能够为常见的数据处理模式提供高效且简洁的解决方案。这种设计使得FlumeJava可以轻松扩展,用户可以基于这些基本操作创建自己的派生操作来解决特定问题。通过这种方式,FlumeJava旨在简化大规模数据处理,并使得编写和维护复杂数据处理管道变得更加容易。
Deferred Evaluation
为了实现下一节中所描述的优化,FlumeJava的并行操作是通过使用延迟计算来懒惰执行的。内部表示的每个PCollection对象要么是延迟的(尚未计算的),要么是实体化的(已计算的)状态。一个延迟的PCollection保存指向计算它的延迟操作的指针。反过来,一个延迟操作持有对其参数PCollections的引用(这些参数本身可能是延迟的或实体化的)以及它的结果的延迟PCollections。当调用像parallelDo()这样的FlumeJava操作时,它只是创建了一个ParallelDo延迟操作对象,并返回指向它的新的延迟PCollection。因此,执行一系列FlumeJava操作的结果是一个由延迟PCollections和操作组成的有向无环图;我们称这个图为执行计划。
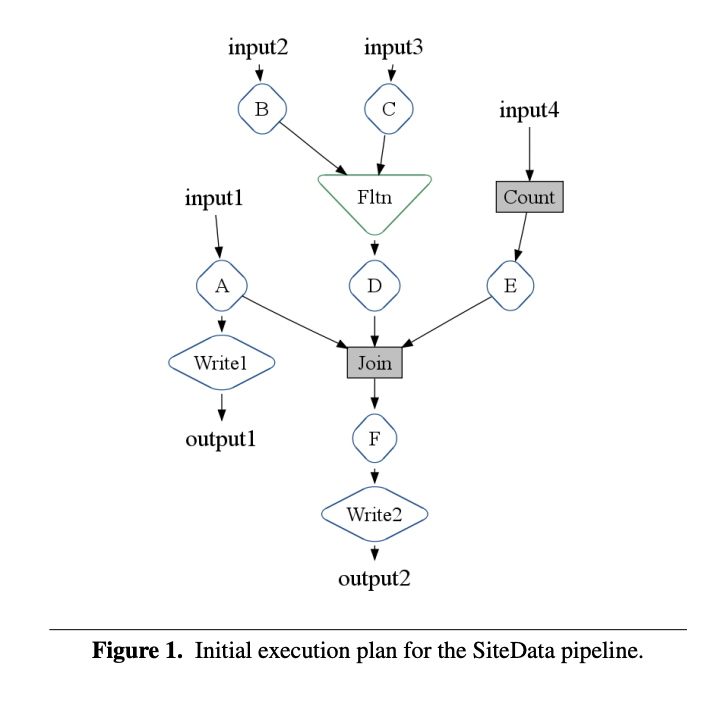
图1展示了用于讨论优化的第4.5节以及作为基准测试的第6节中使用的SiteData示例的执行计划的简化版本。这个管道处理四个不同的输入源,并写入两个输出。(为了简化,我们通常从执行计划图中省略PCollections。)
- Input1由parallelDo() A处理。
- Input2由parallelDo() B处理,Input3由parallelDo() C处理。这两个操作的结果被flatten()ed在一起,然后送入parallelDo() D。
- Input4使用派生操作count()进行计数,结果进一步由parallelDo() E处理。
- 使用派生操作join()将parallelDo() A、D和E的结果结合在一起。其结果进一步由parallelDo() F处理。
- 最终,将parallelDo() A和F的结果写入输出文件。
为了实际触发一系列并行操作的评估,用户在它们之后调用FlumeJava.run()。这首先对执行计划进行优化,然后按照优化计划中的正向拓扑顺序访问每个延迟操作,并评估它们。当评估一个延迟操作时,它将其结果PCollection转换为实体化状态,例如,作为内存中的数据结构或作为对临时中间文件的引用。FlumeJava会自动删除它创建的任何临时中间文件,当这些文件不再被执行计划中的后续操作所需要时。第4节提供了优化器的详细信息,第5节解释了如何执行优化后的执行计划。
解释了FlumeJava是如何通过延迟评估机制来支持大规模数据处理操作的优化的。在FlumeJava中,PCollections和操作(如parallelDo()、groupByKey()等)不是立即执行的,而是构建成了一个执行计划,即一个有向无环图(DAG)。这个图包含了所有的延迟操作和它们的依赖关系。当代码调用FlumeJava.run()时,这个执行计划将会被优化并执行。
优化过程涉及重新排列操作以减少计算量、合并操作以减少数据传输以及其他可能的改进。执行阶段涉及实际运行每个操作,并且根据需要将数据从延迟状态转换到实体化状态,这可能意味着将数据存储在内存中或者写入磁盘。
通过这种方式,FlumeJava程序不必在每个操作后立即处理并存储大量数据,而是可以在执行的最佳时间点以最高效的方式进行。这种延迟计算机制使FlumeJava能够在处理大型数据集时保持高效,同时为优化执行提供了灵活性。
PObjects
FlumeJava为了支持在管道执行过程中和执行完成后检查PCollections的内容,引入了一个名为PObject
例如,应用于PCollection
1 | PTable<String,Integer> wordCounts = ...; |
再举一个例子,应用于PCollection
这些特性可以用来表达需要迭代直到计算数据收敛的计算:
1 | PCollection<Data> results = |
PObjects的内容也可以在管道的执行中被检查。一种方法是使用operate() FlumeJava原语,它接受一组参数PObjects和一个OperateFn,并返回一组结果PObjects。在评估时,operate()会提取其现已实体化参数PObjects的内容,并将它们传递给参数OperateFn。OperateFn应该返回一个Java对象的列表,operate()将其包装在PObjects中,并作为其结果返回。使用这个原语,可以将任意计算嵌入到FlumeJava管道中,并以延迟方式执行。例如,考虑嵌入对一个读取和写入文件的外部服务的调用:
1 | // 计算要爬取的URLs: |
这个例子使用了将PCollections和包含文件名的PObjects之间转换的操作。应用于PCollection和文件格式选择的viewAsFile()操作产生了一个PObject
以非常相同的方式,PObjects的内容也可以在DoFn内部被检查,通过将它们作为边输入(side inputs)传递给parallelDo()。当管道被运行并且parallelDo()操作最终被评估时,任何现已实体化的PObject边输入的内容都被提取出来,提供给用户的DoFn,然后DoFn被调用在输入PCollection的每个元素上。例如:
1 | PCollection<Integer> values = ...; |
在这个例子中,pMaxValue作为一个边输入传递给parallelDo(),允许在处理docInfos的PCollection中的每个DocInfo时访问最大值。
主要介绍了FlumeJava框架中PObject
的概念以及其在管道执行和数据收敛检查中的应用。PObject是一个容器,用于持有并管理单个Java对象。它与PCollection类似,可以是延迟的(即计算尚未执行)或实体化的(计算已完成)。通过PObject,开发者可以在管道执行完毕后获取计算结果。
主要点如下:
- PObject
的使用: PObject可以在管道执行后用于获取计算结果。它类似于未来(future)对象,可以延迟获取值。- asSequentialCollection()操作: 这个操作将PCollection
转换为PObject<Collection >,允许开发者在管道执行结束后审查PCollection的全部元素。 - combine()操作: 该操作可以将PCollection
中的元素全部组合成一个单一的结果,通过提供的组合函数实现,可以用来计算全局总和或最大值。 - 迭代计算和收敛检查: 开发者可以使用PObject来表示计算是否收敛的布尔值,并基于此执行迭代计算,直到数据收敛。
- operate()原语: 该原语使用一组PObject参数和一个操作函数(OperateFn)来执行计算,并返回一组计算结果的PObject。这允许在管道中嵌入任意计算。
- 将PCollections与文件名转换: FlumeJava提供了viewAsFile()等操作来处理PCollections和文件名之间的转换,这些文件名保存在PObject
中,方便后续操作读取。 - 边输入(Side Inputs): 开发者可以将PObject作为边输入传递给parallelDo()操作中的DoFn,当管道执行时,边输入中的值会被提取并提供给DoFn。
总结来说,上段内容强调了PObject在FlumeJava中的灵活性和多功能性,它可以被用于延迟评估和执行管道计算,让开发者在数据处理完成后能够检索和使用计算结果。此外,PObject也能嵌入到FlumeJava管道的中间,作为计算流程中的检查点或调用外部服务。
Optimizer
FlumeJava优化器将用户构建的模块化FlumeJava执行计划转换成一个可以高效执行的计划。优化器是作为一系列独立的图形转换来编写的。
ParallelDo Fusion
最简单和最直观的优化之一是ParallelDo生产者-消费者融合,这本质上是函数组合或循环融合。如果一个ParallelDo操作执行函数f,其结果被另一个执行函数g的ParallelDo操作所消费,那么这两个ParallelDo操作会被替换为一个单一的多输出ParallelDo操作,它同时计算f和g◦f。如果f的ParallelDo结果不被图中的其他操作所需要,那么融合操作就使它变得不必要,生成该结果的代码会被当作死代码移除。
当两个或更多的ParallelDo操作读取相同的输入PCollection时,会应用ParallelDo兄弟融合。它们会被融合成一个单一的多输出ParallelDo操作,在对输入的单次遍历中计算所有融合操作的结果。
无论是生产者-消费者融合还是兄弟融合,都可以应用于多输出ParallelDo操作的任意树形结构。图2展示了一个执行计划片段的例子,在这个例子中,ParallelDo操作A、B、C和D可以被融合成一个单一的ParallelDo A+B+C+D。这个新的ParallelDo创建了原始图中的所有叶子输出,加上输出A.1,因为它被其他非ParallelDo操作Op所需要。中间输出A.0不再需要,因而被融合掉。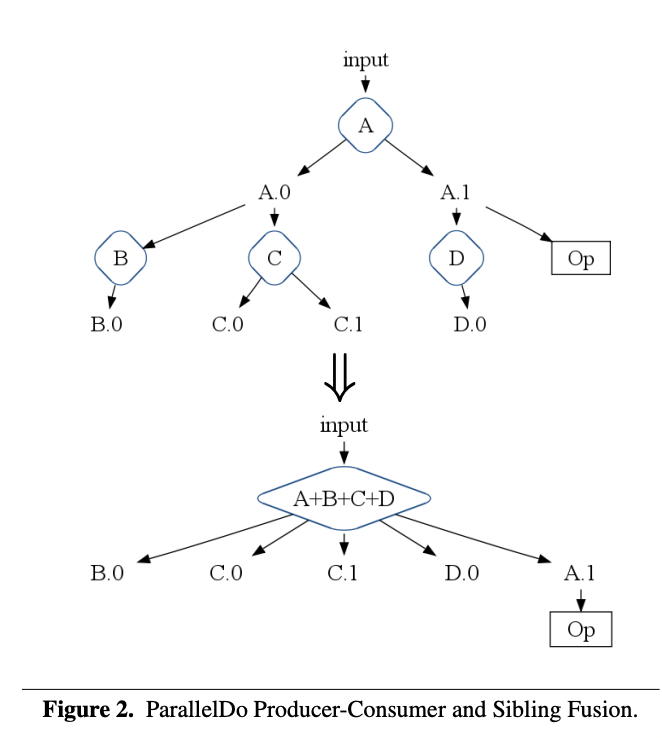
如前所述,CombineValues操作是特殊情况的ParallelDo操作,它们可以被重复应用于部分计算的结果。因此,ParallelDo融合也适用于CombineValues操作。
这段内容讲述了FlumeJava中针对优化执行计划的一种策略,即ParallelDo操作的融合。融合是编程中一个常见的优化技术,它试图将多个操作合并成一个操作。在FlumeJava中,这种融合主要有两种情况:
- 生产者-消费者融合(Producer-Consumer Fusion)
- 兄弟融合(Sibling Fusion)
这样的融合优化不仅减少了数据的中间状态产生和存储,也减少了遍历输入数据的次数,从而提高了整体计算的效率。在提到的执行计划片段的例子中,通过融合操作,可以减少中间输出的产生,只在需要的地方输出数据。
此外,CombineValues操作,作为特殊的ParallelDo操作,也可以通过融合技术来优化,因为它们可以在部分计算结果上反复应用,合并更小的数据集合成为更大的集合,直至最终结果。
通过这些连续的图形转换和融合优化,FlumeJava优化器能够生成一个更加高效执行的数据处理流程。
The MapShuffleCombineReduce (MSCR) Operation
FlumeJava优化器的核心将ParallelDo、GroupByKey、CombineValues和Flatten操作的组合转换成单个MapReduce操作。为了帮助弥合这两个抽象层次之间的差距,FlumeJava优化器包括了一个中间层次的操作,即MapShuffleCombineReduce(MSCR)操作。一个MSCR操作有M个输入通道(每个执行一个map操作)和R个输出通道(每个可选地执行一个shuffle,一个可选的combine和一个reduce)。每个输入通道m接收一个PCollection作为输入,并在该输入上执行一个R输出的ParallelDo“map”操作(默认为身份操作),以产生R个类型为PTable<Kr,Vr>的输出;输入通道可以选择只向它可能的输出通道中的一个或几个发射数据。每个输出通道r Flatten它的M个输入,然后要么(a)执行一个GroupByKey“shuffle”,一个可选的CombineValues“combine”,和一个Or输出的ParallelDo“reduce”(默认为身份操作),然后将结果写入Or个输出PCollections,要么(b)直接将其输入作为输出写出。前一种类型的输出通道被称为“分组”通道,而后一种类型的输出通道被称为“直通”通道;一个直通通道允许mapper的输出成为一个MSCR操作的结果。
MSCR通过允许多个reducers和combiners,允许每个reducer产生多个输出,移除reducer必须产生与reducer输入相同键的输出的要求,以及允许直通输出,从而使其成为我们优化器的更好目标。尽管看起来表现力更强,但每个MSCR操作都是使用单个MapReduce来实现的。
图3展示了一个MSCR操作,有3个输入通道分别执行ParallelDos M1、M2和M3,两个分组输出通道,每个都有一个GroupByKey、CombineValues和reducing ParallelDo,以及一个直通输出通道。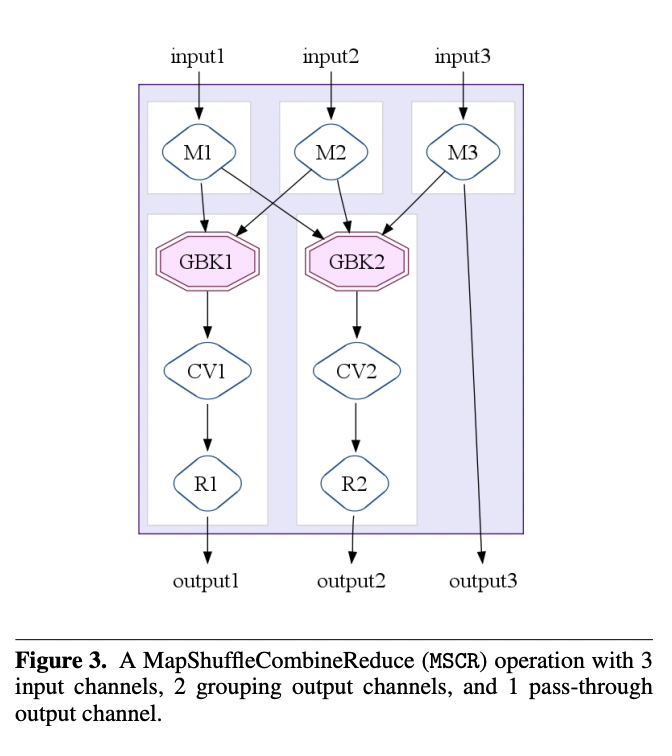
FlumeJava优化器主要负责将用户编写的执行计划转化为能够高效执行的MapReduce作业。为此,它引入了MSCR操作作为中间层次的抽象,它更加贴近MapReduce模型,但比它更加灵活和强大。
- 输入通道(Input Channels): MSCR操作的每个输入通道处理一个PCollection,并可以执行一个map操作,该操作产生R个输出,每个输出属于不同的类型。
- 输出通道(Output Channels): MSCR操作的每个输出通道则处理来自输入通道的数据。它可以执行shuffle(类似于GroupByKey)、可选的combine(类似于CombineValues)和reduce操作。输出通道分为两种类型:分组通道(需要shuffle、combine和reduce)和直通通道(不需要这些操作,直接将输入作为输出)。
MSCR抽象模型广泛地泛化了MapReduce:
- 允许多个reducers和combiners。
- 允许每个reducer产生多个输出。
- 不要求reducer的输出必须与其输入具有相同的键。
- 允许直通输出。
这使得MSCR能够更好地适应FlumeJava优化器的需求,实现更复杂的优化策略。
尽管MSCR看似功能更丰富,但它在实现时仍然是基于单个MapReduce作业。这意味着MSCR能够将多个操作有效地组合到一个MapReduce作业中,减少了数据移动和作业调度的开销,提高了整体数据处理的效率。
MSCR Fusion
MSCR操作是从一组相关的GroupByKey操作中产生的。如果GroupByKey操作消费(可能通过Flatten操作)相同的输入,或者由相同的(已融合的)ParallelDo操作创建的输入,则认为这些GroupByKey操作是相关的。
MSCR的输入和输出通道是从相关的GroupByKey操作和执行计划中相邻操作中衍生出来的。每个至少有一个输出被其中一个GroupByKey操作(可能通过Flatten操作)消费的ParallelDo操作被融合到MSCR中,形成一个新的输入通道。GroupByKeys的任何其他输入也形成具有身份映射器的新输入通道。每个相关的GroupByKey操作都启动一个输出通道。如果GroupByKey的结果仅被CombineValues操作消费,那么该操作被融合到相应的输出通道中。同样,如果GroupByKey的或融合后的CombineValues的结果仅被ParallelDo操作消费,那么该操作也被融合到输出通道中,如果它无法被融合到不同MSCR的输入通道中。所有融合了ParallelDo、GroupByKey和CombineValues操作的内部PCollections现在是不必要的,因此被删除。最后,每个流向除了相关GroupByKeys之外的操作或输出的mapper ParallelDo的输出都生成自己的直通输出通道。
图4展示了一个示例执行计划如何被融合成MSCR操作。在这个例子中,所有三个GroupByKey操作都是相关的,因此成为了单个MSCR操作的种子。GBK1与GBK2相关,因为它们都消费了ParallelDo M2的输出。GBK2与GBK3相关,因为它们都消费了PCollection M4.0。ParallelDos M2、M3和M4被合并为MSCR输入通道。每个GroupByKey操作都成为一个分组输出通道。GBK2的输出通道合并了CV2 CombineValues操作。R2和R3 ParallelDos也被合并到输出通道中。为了GBK1从非ParallelDo Op1的输入创建了一个额外的身份输入通道。为了MSCR后使用的M2.0和M4.1 PCollections,创建了两个额外的直通输出通道(显示为从mappers到outputs的边)。结果MSCR操作有4个输入通道和5个输出通道。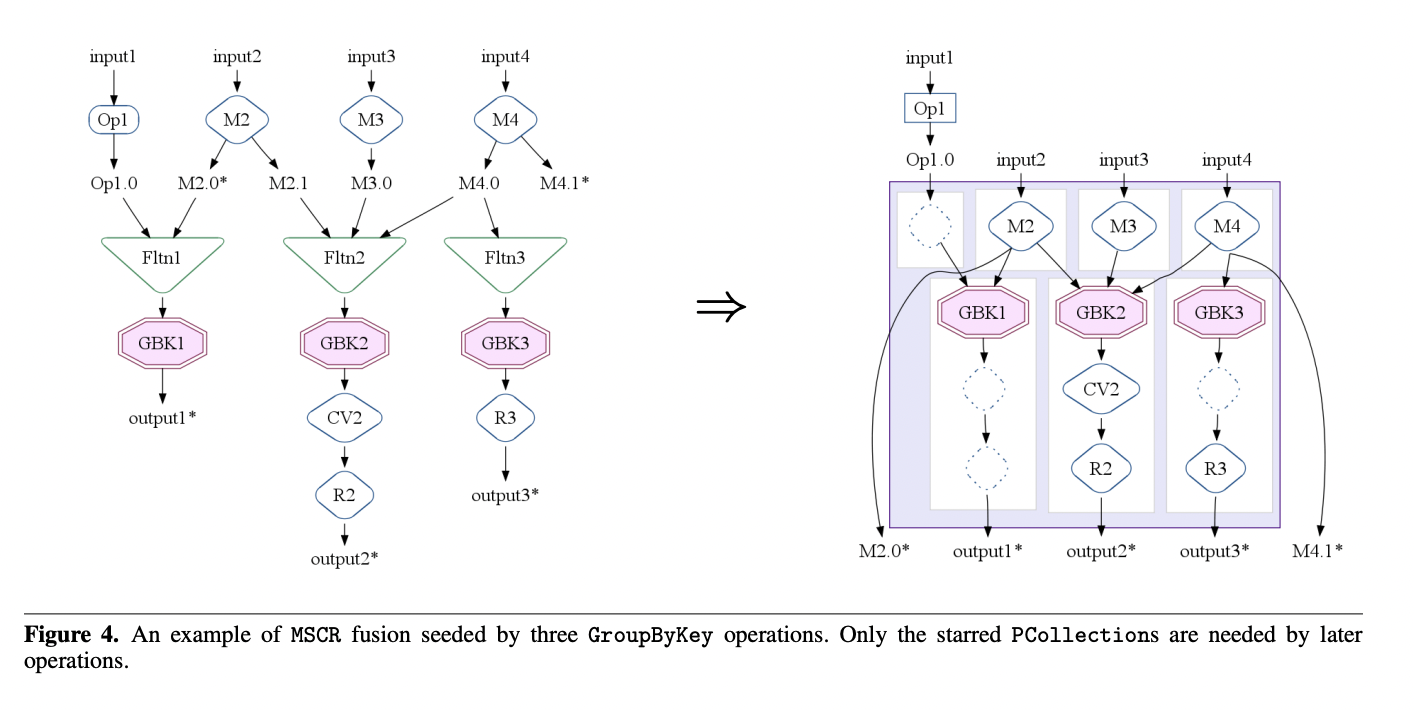
在所有GroupByKey操作被转换为MSCR操作之后,任何剩余的ParallelDo操作也被转换为带有单个输入通道的简单MSCR操作,输入通道包含ParallelDo和单个直通输出通道。最终优化的执行计划只包含MSCR、Flatten和Operate操作。
Overall Optimizer Strategy
优化器对执行计划进行一系列遍历,其总体目标是在最终优化的计划中生成最少量、最高效的MSCR操作:
- 下沉Flattens(Sink Flattens)。Flatten操作可以通过在Flatten的每个输入前复制消费它的ParallelDo操作来下沉(推迟执行)。用符号表示,就是将h(f(a) + g(b))转换为h(f(a)) + h(g(b))。这种转换为ParallelDo融合创造了机会,例如,(h ◦ f)(a) + (h ◦ g)(b)。
- 抬升CombineValues操作(Lift CombineValues operations)。如果CombineValues操作紧跟在GroupByKey操作之后,GroupByKey记录这个情况。原始的CombineValues保留在原位,从此被视为一个普通的ParallelDo操作,并且受到ParallelDo融合的影响。
- 插入融合块(Insert fusion blocks)。如果两个GroupByKey操作通过一个或多个ParallelDo操作的生产者-消费者链连接,优化器必须选择哪些ParallelDos应该融合“上升”到较早GroupByKey的输出通道中,哪些应该融合“下沉”到后面GroupByKey的输入通道中。优化器估计链上各个ParallelDos的中间PCollections的大小,识别出一个预期大小最小的,并将其标记为阻止ParallelDo融合的边界。
- 融合ParallelDos(Fuse ParallelDos)。
- 融合MSCRs(Fuse MSCRs)。创建MSCR操作。将任何剩余未融合的ParallelDo操作转换为简单的MSCR。
Example: SiteData
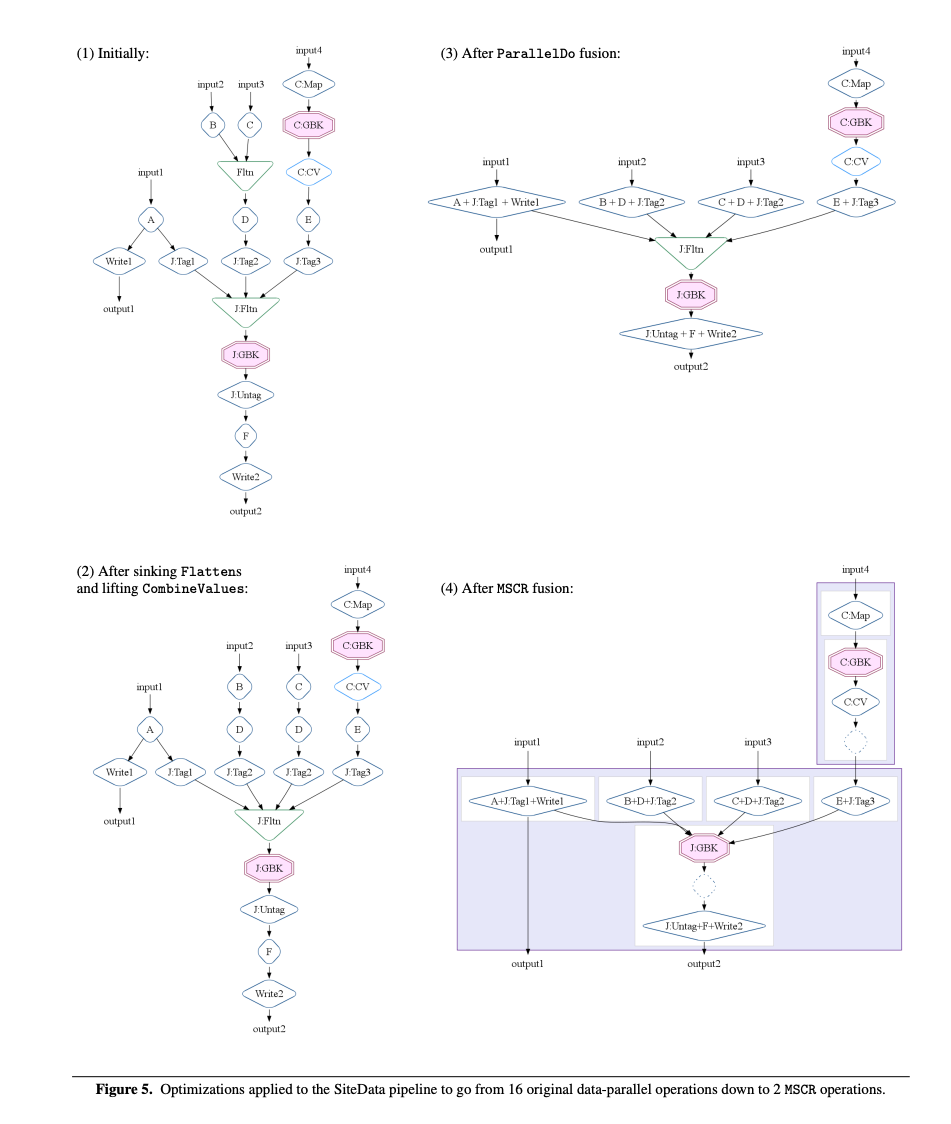
在本节中,我们展示了优化器如何在第3.3节介绍的SiteData管道上工作。图5显示了最初的执行计划以及每个主要优化阶段之后的执行计划。
- 最初阶段。最初的执行计划是由诸如parallelDo()和flatten()等原语的调用以及由对低级操作的调用实现的派生操作如count()和join()构建的。在这个例子中,count()调用扩展为包括ParallelDo C:Map、GroupByKey C:GBK和CombineValues C:CV操作,而join()调用扩展为包括标记每个输入集合的ParallelDo操作J:TagN、Flatten J:Fltn、GroupByKey J:GBK以及处理结果的ParallelDo J:Untag操作。
- 在下沉Flattens和抬升CombineValues之后。Flatten操作J:Fltn被推下通过消费它的ParallelDo操作D和J:Tag:2。CombineValues操作C:CV的一个副本与C:GBK关联。
- 在ParallelDo融合之后。生产者-消费者融合和兄弟融合被应用到相邻的ParallelDo操作。由于融合块的设置,CombineValues操作C:CV没有与ParallelDo操作E+J:Tag3融合。
- 在MSCR融合之后。GroupByKey操作C:GBK和周围的ParallelDo操作融合成一个第一MSCR操作。GroupByKey操作iGBK和J:GBK成为第二个MSCR操作的核心操作,其中包括剩余的ParallelDo操作。
最初的执行计划包含了16个数据并行操作(ParallelDos、GroupByKeys和CombineValues)。最终优化后的计划只有两个MSCR操作。
Optimizer Limitations and Future Work
优化器不会分析用户编写的函数内部的代码(例如,传递给parallelDo()操作的DoFn参数)。它基于执行计划的结构以及用户可以提供的一些可选提示来做出优化决策。这些提示提供了关于某些操作行为的信息,如DoFn输出数据大小相对于其输入数据大小的估计。如果进行用户代码的静态分析,或许可以实现更好的优化和/或减少用户手动引导的需要。
同样地,优化器在其优化过程中不会修改任何用户代码。例如,它通过简单的类AST(抽象语法树)数据结构来表示融合后的DoFn的结果,该结构说明了如何运行用户的代码。通过生成新代码来表示用户函数的适当组合,然后对生成的代码应用传统的优化技术如内联,可以实现更好的性能。
用户发现编写FlumeJava管道非常容易,因此他们经常编写大型且有时效率不高的程序,其中包含重复和/或不必要的操作。优化器可以通过增加额外的公共子表达式消除(common-subexpression elimination)来避免重复。此外,用户倾向于比必要时更频繁地包括groupByKey()操作,仅仅因为在逻辑上对他们来说,按键对数据进行分组是有意义的。优化器应该被扩展以识别和移除不必要的groupByKey()操作,例如当一个groupByKey()的结果被输入到另一个groupByKey()时(可能在join()操作的伪装下)。
Executor
一旦执行计划被优化,FlumeJava库就会运行它。目前,FlumeJava支持批处理执行:FlumeJava按照前向拓扑顺序遍历计划中的操作,并依次执行每个操作。独立的操作可以同时执行,支持一种任务并行性,这种并行性与操作内部的数据并行性相辅相成。最有趣的执行操作是MSCR。FlumeJava首先决定该操作是应该在本地依次运行,还是作为一个远程的并行MapReduce运行。由于启动一个远程并行作业会有开销,对于那些由于并行处理的收益被启动的开销所抵消的中等大小的输入数据,本地评估是首选。在开发和测试期间,中等大小的数据集是很常见的,通过对这些数据集使用本地的、进程内评估,FlumeJava便利了使用常规的IDE、调试器、分析器和相关工具,极大地简化了开发包括数据并行计算在内的程序的任务。
如果输入数据集看起来很大,FlumeJava会选择启动一个远程的并行MapReduce。它使用对输入数据大小的观察和对输出数据大小的估计来自动选择合理数量的并行工作机器。用户可以通过增加一种方法到DoFn来协助估计输出数据大小,这种方法返回输出数据大小与输入数据大小的预期比例,基于该DoFn所代表的计算。在未来,我们希望通过动态监控和反馈观察到的输出数据大小来完善这些估计,并且还希望为那些CPU与I/O比率较高的作业分配相对更多的并行工作者。
FlumeJava自动创建临时文件来保存它执行的每个操作的输出。它会自动删除这些临时文件,一旦它们不再被管道后面的其他未评估操作所需要。
FlumeJava努力使构建和运行管道感觉尽可能像运行一个常规的Java程序。对中等大小的输入使用本地、顺序评估是一种方式。另一种方式是通过自动将用户DoFn内部的任何输出到System.out或System.err的输出,比如调试打印语句,从相应的远程MapReduce工作者路由到主FlumeJava程序的输出流。同样,在远程MapReduce工作者上运行的DoFn内抛出的任何异常都会被捕获,发送到主FlumeJava程序,并重新抛出。
在开发一个大型管道时,找到一个在后期管道阶段的bug,修复程序,然后从头开始重新执行修正后的管道可能是耗时的,特别是当不可能在小型数据集上调试管道时。为了帮助这个循环过程,FlumeJava库支持一个缓存执行模式。在这种模式下,FlumeJava首先尝试重用上一次运行保存在(内部或用户可见的)文件中的该操作的结果,如果FlumeJava确定该操作的结果没有改变的话。如果(a)操作的输入没有改变,以及(b)操作的代码和捕获的状态没有改变,那么认为操作的结果是未改变的。FlumeJava执行一个自动的、保守的分析来识别何时可以保证安全地重用以前的结果;用户可以指导重用额外的以前的结果。缓存可以导致快速的编辑-编译-运行-调试循环,即使是通常需要几小时才能运行的管道。
FlumeJava目前实现了一个批处理评估策略,一次针对单个管道。在将来,尝试更增量化、流式化或连续执行管道会很有趣,其中增量添加的输入导致输出的快速、增量更新。调查针对由多个用户在公共数据源上运行的管道之间的跨管道优化也将是一个有趣的课题。
描述的是FlumeJava库如何优化和执行数据处理管道的执行计划。FlumeJava使用批处理执行模式,它会根据数据的大小决定是本地顺序执行还是远程并行MapReduce执行。库会自动处理操作的输出和临时文件,并尽量让编写和运行管道的过程像编写常规Java程序一样简单。
对于大型任务的开发,FlumeJava提供缓存执行模式,以加速调试和开发周期。这种模式允许复用之前运行的结果,从而避免重复计算。最后,文本也提到了对未来可能发展的方向,包括流式执行管道和跨用户管道优化。
Evaluation
我们已经实现了FlumeJava库、优化器和执行器,这些都是基于谷歌提供的MapReduce和其他低层级服务构建的。在这一节中,我们将介绍FlumeJava在实际中是如何被使用的,并且通过实验显示FlumeJava优化器和执行器使得模块化、清晰的FlumeJava程序的运行表现几乎和它们经过手动优化的原生MapReduce基础版本一样好。
User Adoption and Experience
衡量FlumeJava系统效用的一个指标是实际开发者在多大程度上觉得它值得转换使用,相比他们已经熟悉并在使用的系统。这是我们评估FlumeJava编程抽象和API的主要方式。
自2009年5月初次发布以来,FlumeJava在谷歌内部得到了显著的用户接纳和生产使用。为了测量使用情况,我们对FlumeJava库进行了代码插桩,以便每次运行FlumeJava程序时记录一条使用记录。下表提供了一些从这些日志中衍生出的统计数据,截至2010年3月中旬。N天活跃用户数给出了在过去N天内运行了FlumeJava程序(排除了固定教程程序)的不同用户ID数量。
| 1-day active users | 62 |
|---|---|
| 7-day active users | 106 |
| 30-day active users | 176 |
| Total users | 319 |
数百个FlumeJava程序已被编写并签入谷歌内部的源代码库。单个FlumeJava程序已成功地在数千台机器上处理了PB级别的数据。
总的来说,用户似乎非常满意FlumeJava的抽象。他们并不总是那么满意Java的某些方面,或者FlumeJava对Java的使用。特别是,Java对简单匿名函数和异质元组的支持不好,这导致代码冗长并且在某种程度上失去了静态类型安全。此外,FlumeJava基于PCollection的数据并行模型隐藏了许多有关单个并行工作机器的细节以及Mapper和Reducer之间的微妙差异,这使得表达某些由一些高级MapReduce用户使用的低层级并行编程技巧变得困难。
FlumeJava现在被计划成为谷歌基于Java的主要数据并行计算API。
Optimizer Effectiveness
为了研究FlumeJava优化器在减少并行MapReduce阶段数量的有效性,我们对FlumeJava系统进行了代码插桩,以便它可以记录用户管道的结构,在优化之前和之后。下面的散点图显示了从这些日志中提取的结果。图中的每个点代表一个或多个用户管道以及对应的阶段数量。为了提高图的可读性,我们移除了大约10个具有超过120个未优化阶段的较大管道的数据。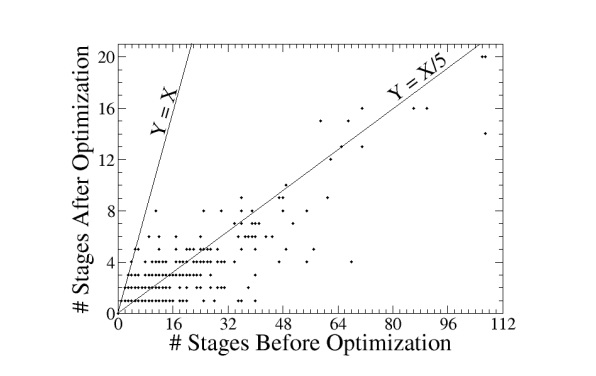
通过观察用户管道在优化前后的大小,很明显,FlumeJava已经被用于编写规模从小到相当大的管道。事实上,到目前为止最大的管道(未绘制在图中)有820个未优化阶段和149个优化阶段。这些数据进一步强调了FlumeJava API的易用性。
观察优化器的“压缩”比率(优化前后阶段数量的比率),优化器似乎平均能够实现5倍的阶段数量减少,有些管道的压缩比率超过30倍。一个管道(未绘制在图中)有207个未优化阶段,它们被融合成一个优化后的阶段。
FlumeJava优化器本身运行速度很快,特别是与优化后的实际执行相比。对于有几十个操作的管道,优化器通常在一两秒内就完成了。
Execution Performance
FlumeJava的目标是让程序员以清晰、模块化的方式表达他或她的并行数据计算,同时执行它以接近直接对MapReduce API编写的最佳手动优化程序的性能。虽然高的优化器压缩率是好事,但真正的目标是缩短执行时间。
为了评估FlumeJava实现这一目标的程度,我们首先基于FlumeJava用户编写的真实管道构建了几个基准程序。这些基准程序执行不同的计算任务,包括分析广告日志(Ads Logs)、从不同来源提取和连接有关网站的数据(SiteData 和 IndexStats),以及计算内部构建工具转储日志的使用统计(Build Logs)。
我们以三种不同的方式编写了每个基准测试:
- 使用FlumeJava以模块化风格编写,
- 使用Java MapReduce以模块化风格编写,
- 使用Java MapReduce以手动优化风格编写。 对于两个基准测试,我们还以第四种方式编写:
- 使用Sawzall以手动优化风格编写,Sawzall是一种在MapReduce之上实现的领域特定日志处理语言。 模块化Java MapReduce风格反映了FlumeJava程序中的逻辑结构,但它并非通常在MapReduce中表达此类计算的方式。手动优化风格代表了计算的高效执行策略,在实践中更为常见,但由于是手动优化并直接用MapReduces表示,逻辑计算可能变得模糊且难以改变。手动优化的Sawzall版本同样混合了逻辑计算与底层实现细节,以获得更好的性能。
下表显示了编写每个基准测试的每个版本所需的源代码行数:
| Benchmark | FlumeJava | MapReduce(Modular) | MapReduce(Hand-Opt) | Sawzall |
|---|---|---|---|---|
| 广告日志(Ads Logs) | 320 | 465 | 399 | 158 |
| 索引状态(IndexStats) | 176 | 296 | 336 | - |
| 计算内部构建工具转储日志的使用统计(Build Logs) | 276 | 476 | 355 | - |
| 页面数据(Site Data) | 465 | 653 | 625 | 261 |
对于每个案例,FlumeJava版本都比使用原始Java MapReduce编写的等效版本更简洁。Sawzall比Java更简洁。
下表为FlumeJava版本提供了管道中FlumeJava操作的数量(优化前后),对于Java MapReduce和Sawzall版本,则提供了MapReduce阶段的数量:
| Benchmark | FlumeJava | MapReduce(Modular) | MapReduce(Hand-Opt) | Sawzall |
|---|---|---|---|---|
| 广告日志(Ads Logs) | 14->1 | 4 | 1 | 4 |
| 索引状态(IndexStats) | 16->2 | 3 | 2 | - |
| 计算内部构建工具转储日志的使用统计(Build Logs) | 7->1 | 3 | 1 | - |
| 页面数据(Site Data) | 12->2 | 5 | 2 | 6 |
对于每个基准测试,FlumeJava版本中自动优化的操作数量与相应的手动优化MapReduce版本中的MapReduce阶段数量相匹配。作为一种更高级的、领域特定的语言,Sawzall无法为程序员提供足够的底层访问权限,使他们能够手动优化程序以达到这种最小数量的MapReduce阶段,也不包括自动优化器。
下表显示了每个基准测试的输入数据集大小和我们用来运行它的工作机器数量:
| Benchmark | Input Size | Number of Machines |
|---|---|---|
| 广告日志(Ads Logs) | 550MB | 4 |
| 索引状态(IndexStats) | 3.3TB | 200 |
| 计算内部构建工具转储日志的使用统计(Build Logs) | 34GB | 15 |
| 页面数据(Site Data) | 1.3TB | 200 |
我们比较了每个基准测试不同版本的运行时性能。我们确保每个版本使用了相同数量的机器和其他资源。我们测量了MapReduce工作节点运行时花费的总计墙钟时间;我们排除了启动主控制程序、将编译好的二进制文件分发到工作机器和清理临时文件的“协调”时间。由于执行时间可能在不同运行之间显著变化,我们对每个基准测试版本运行了五次,并将测量到的最小时间作为近似的“真实”时间,以排除在共享机器集群上运行的无关影响。
下面的图表显示了每个基准测试的每个版本的经过时间,相对于FlumeJava版本的经过时间(更短的条形表示更好):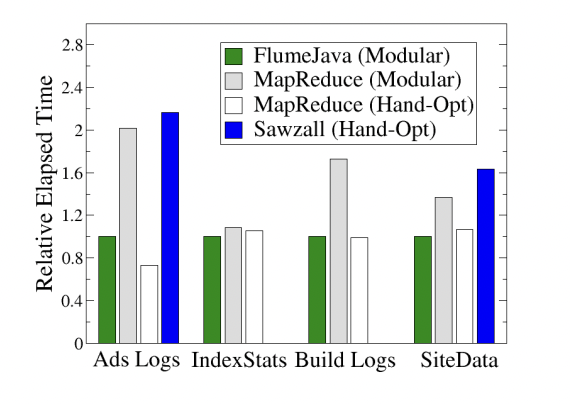
比较两个MapReduce列和Sawzall列显示了优化的重要性。没有优化,工作节点的设置开销、为了存储中间数据而产生的额外I/O、额外的数据编码和解码时间以及其他类似因素增加了产生输出所需的整体工作量。比较FlumeJava和手动优化MapReduce列显示,使用FlumeJava编写的模块化程序的性能接近使用底层MapReduce API的手动优化版本。
Related Work
在本节中,我们简要描述了相关工作,并将FlumeJava与这些工作进行了比较。
用于数据并行编程的语言和库支持有着悠久的历史。早期的工作包括Lisp、C、C**和pH。
MapReduce结合了简单的抽象来进行数据并行处理,并且实现了高效、高可扩展性、容错性强的执行。MapReduce的抽象直接支持可以被表示为映射步骤、洗牌步骤和归约步骤的计算。MapReduce可以用几种语言编程,包括C++和Java。FlumeJava建立在Java MapReduce之上,提供了更高级别、更可组合的抽象,并且有一个优化器来从这些抽象中恢复良好的性能。
FlumeJava内置了对管理MapReduce管道的支持。FlumeJava还提供了额外的便利性,使得开发FlumeJava程序类似于开发一个常规的单进程Java程序。
Sawzall是一种在MapReduce之上实现的特定领域的日志处理语言。Sawzall程序可以灵活地指定MapReduce的映射器部分,只要映射器是纯函数。Sawzall包含了一打标准归约器的库;用户不能指定他们自己的归约器。这限制了Sawzall用户为某些计算(如连接)表达高效执行计划的能力。与MapReduce一样,Sawzall不提供对多阶段管道的帮助。
Hadoop是MapReduce的开源Java重新实现,配有工作调度器和分布式文件系统,类似于Google文件系统。因此,当开发多阶段管道时,Hadoop具有与MapReduce类似的限制。
Cascading是建立在Hadoop之上的Java库。与FlumeJava一样,Cascading旨在简化编程数据并行管道的挑战,并提供与FlumeJava类似的抽象。与FlumeJava不同,Cascading程序显式地构建一个数据流图。此外,流经Cascading管道的值是特殊的无类型“元组”值,Cascading操作侧重于元组的转换;相比之下,FlumeJava管道通过使用任意Java计算来计算任意Java对象。Cascading在运行它们之前对其数据流图进行一些优化。类似于FlumeJava的执行器,Cascading评估器将数据流图分解为部分,并且如果可能的话,使用底层的Hadoop作业调度器并行运行它们。有一种机制,如果输入数据未更改,则省略计算,类似于FlumeJava的缓存机制。
Pig将一种特殊的特定领域的语言Pig Latin编译成在Hadoop上运行的代码。Pig Latin程序结合了高级声明式操作符(类似于SQL中的操作符),以及表示操作符之间数据流图边的命名中间变量。该语言允许用户定义的转换和提取函数,并提供对共组和连接的支持。Pig系统有一个新颖的调试机制,它可以生成说明各种操作的示例数据集。Pig系统有一个优化器,试图最小化Hadoop作业之间物化的数据量,并对输入数据集的大小敏感。
Dryad系统实现了一个通用的数据并行执行引擎。Dryad程序是用C++编写的,使用重载运算符来指定一个任意的非循环数据流图,有点类似于Cascading的显式图构建模型。与MapReduce一样,Dryad处理通信、分区、放置、并发和容错的细节。与原始MapReduce不同但与FlumeJava优化器的MSCR原语类似,计算节点可以有多个输入和输出边“通道”。与FlumeJava不同,Dryad没有优化器来组合或重新排列数据流图中的节点,因为节点是计算黑盒,但Dryad确实包括通过用户可以执行某些优化类型的运行时图细化的概念。
C# 3.0的LINQ扩展为C#添加了类似SQL的构造。这个构造是一系列库调用的语法糖,可以针对不同类型的被“查询”的数据进行不同的实现。可以使用类似SQL的构造对传统的关系数据(并发送到远程数据库服务器)、对XML数据以及对内存中的C#对象进行查询。它也可以用来表示并行计算并在Dryad上执行。类似SQL的构造解糖成调用以构建原始查询的内部表示的方式,与FlumeJava的并行操作隐式构建内部执行计划的方式类似。DryadLINQ还包括类似于FlumeJava中的优化。为了支持LINQ,C#语言进行了大幅度的扩展;与之形成对比的是,FlumeJava是作为一个纯Java库实现的,没有语言改变。DryadLINQ要求通过单个类似SQL的声明来表达管道。与之相反,对FlumeJava操作的调用可以与其他Java代码混合,组织成函数,并用传统的Java控制流操作管理;延迟评估使所有这些调用可以动态合并成一个单一的管道,然后作为一个单元进行优化和执行。
SCOPE 是基于Dryad之上构建的一种声明式脚本语言。程序是用一种SQL的变体编写的,带有扩展,用于调用用C#编写的自定义提取器、过滤器和处理器。C#扩展与SQL代码混合在一起。与Pig Latin一样,SQL查询被分解为一系列不同的步骤,中间流由变量命名。SQL框架提供了命名的数据字段,但在扩展代码中似乎很少有对这些名称的支持。优化器使用传统的查询优化规则转换SQL表达式,连同新的规则,考虑到数据和通信的局部性。
Map-Reduce-Merge 通过添加额外的Merge步骤扩展了MapReduce模型,使得可以在单次执行中表达额外类型的计算,例如关系代数。FlumeJava支持更通用的管道。
FlumeJava的优化器与传统编译器优化共享许多概念,例如循环融合和公共子表达式消除。FlumeJava的优化器还与数据库查询优化器有一定相似性:它们都是从逻辑计算的更高级描述中生成优化的执行计划,都可以优化执行连接操作的程序。然而,数据库查询优化器通常使用关系数据库中有关输入表的运行时信息,例如它们的大小和可用索引,来选择一个高效的执行计划,例如用哪种算法来计算连接。与之相反,FlumeJava没有内置对连接的支持。相反,join()是一个派生的库操作,它实现了特定的连接算法,即hash-merge-join,即便是对于缺乏索引的简单基于文件的数据集来说,这个算法也能使用MapReduce实现。其他连接算法可以通过其他派生库操作实现。FlumeJava的优化器比典型的数据库查询优化器工作在更低的层次上,对join()库操作的底层原语应用融合和其他简单转换。它在不参考输入的大小或其他表现属性的情况下选择如何优化。事实上,在大型管道中嵌入连接操作的情况下,这样的信息可能直到优化后的管道部分运行后才会变得可用。FlumeJava的方法允许实现连接操作的操作在周围管道的上下文中被优化;在许多情况下,连接操作完全融合到了计算的其他部分中(反之亦然)。这一点在第4.5节的SiteData例子中有所展示。
在FlumeJava之前,我们正在开发一个基于类似抽象的系统,但是是在一个名为Lumberjack的新编程语言的上下文中提供给用户的。Lumberjack被设计成特别适合表达数据并行管道,包括隐式并行的大部分函数式编程模型、复杂的多态类型系统、局部类型推断、轻量级元组和记录,以及一等公民的匿名函数。Lumberjack由一个强大的优化器支持,包括传统的优化,例如内联和值流分析,以及非传统的优化,例如并行循环的融合。Lumberjack程序被转换为低级中间表示,这在我们的实现中是解释性的,但我们计划最终将其动态转换为Java字节码或本机机器代码。Lumberjack的并行运行时系统与FlumeJava的运行时系统有许多相同的特性。
虽然基于Lumberjack的Flume版本为程序员提供了许多好处,但与FlumeJava版本相比,它有几个重要的缺点:
- 由于Lumberjack是专门为这项任务设计的,Lumberjack程序比等价的FlumeJava程序明显更简洁。然而,隐式并行,大部分函数式编程模型对于其预期的许多用户并不自然。FlumeJava明确并行的模型,区分了Collection和PCollection,以及iterator()和parallelDo(),连同其“大多数命令式”的模型,仅在DoFn边界之间禁止可变共享状态,对于这些程序员来说更自然。
- Lumberjack的优化器是一个传统的静态优化器,在执行程序的任何部分之前,它对程序的内部表示进行优化。由于FlumeJava是一个纯库,它不能使用传统的静态优化方法。相反,我们采用了一种更动态的优化方法,即运行用户程序先构建一个执行计划(通过延迟评估),然后在执行之前优化该计划。FlumeJava不对源程序进行静态分析,也不进行动态代码生成,这在运行时性能上带来了一些成本;这些成本证明是相对适度的。另一方面,能够简单地运行FlumeJava程序来构建完全展开的执行计划,事实证明是巨大的优势。Lumberjack优化器推断程序执行计划的能力总是受到其静态分析强度的限制,但FlumeJava的动态优化器没有这样的限制。实际上,FlumeJava程序员通常在他们的管道计算代码中使用复杂的控制结构和存储PCollections的Collections和Maps。这些编码模式会挫败我们可以合理开发的任何静态分析,但FlumeJava的动态优化器不受这种复杂性的影响。稍后,如果我们希望减少剩余的开销,我们可以为FlumeJava增加一个动态代码生成器。
- 建一个高效、完整、可用的基于Lumberjack的系统比构建一个同样高效、完整和可用的FlumeJava系统要困难和耗时得多。事实上,我们在一年多的努力之后只构建了一个基于Lumberjack的系统的原型,但我们能够改变方向并在短短几个月内构建一个有用的FlumeJava系统。
- 新颖性是采纳的障碍。通过嵌入到一个众所周知的编程语言中,FlumeJava将潜在采纳者的注意力集中在少数新功能上,即Flume抽象和实现它们的几个Java类和方法。潜在的采纳者不会被新语法或新类型系统或新评估模型分散注意力。他们的正常开发工具和实践继续工作。他们所学过并依赖的所有标准库仍然可用。他们不必担心Java会消失并使他们的项目陷入困境。相比之下,Lumberjack在这些方面受到了巨大的影响。它专门设计的语法和类型系统的优势不足以克服这些现实世界的障碍。
Conclusion
FlumeJava是一个纯Java库,它提供了一些简单的抽象来编程数据并行计算。这些抽象比MapReduce提供的抽象更高级,为管道提供了更好的支持。FlumeJava内部使用了一种延迟评估的形式,使得管道可以在执行前进行优化,从而实现接近手动优化MapReduce的性能。FlumeJava的运行时执行器可以在不同的实现策略之间选择,允许相同的程序在小的测试输入上完全本地执行,并在大的输入上使用许多并行机器执行。FlumeJava在谷歌正在积极地、生产性地使用。它的采纳得益于它只是一个“普通”的库。