Flink-Source-2 SourceReaderBase 流程
本文着重描述了 SourceReaderBase 实现逻辑,但是在描述 SourceReader 之前,肯定是需要了解与之关系密切的 SplitEnumerator 的行为,由于 SplitEnumerator 仅提供了一个接口,我们要确定多数情况下的实现,SplitEnumerator 是如何与 SourceReader 进行交互的,毕竟 Source 的起点是在 JobManager 的 SplitEnumerator 之中。
SplitEnumerator
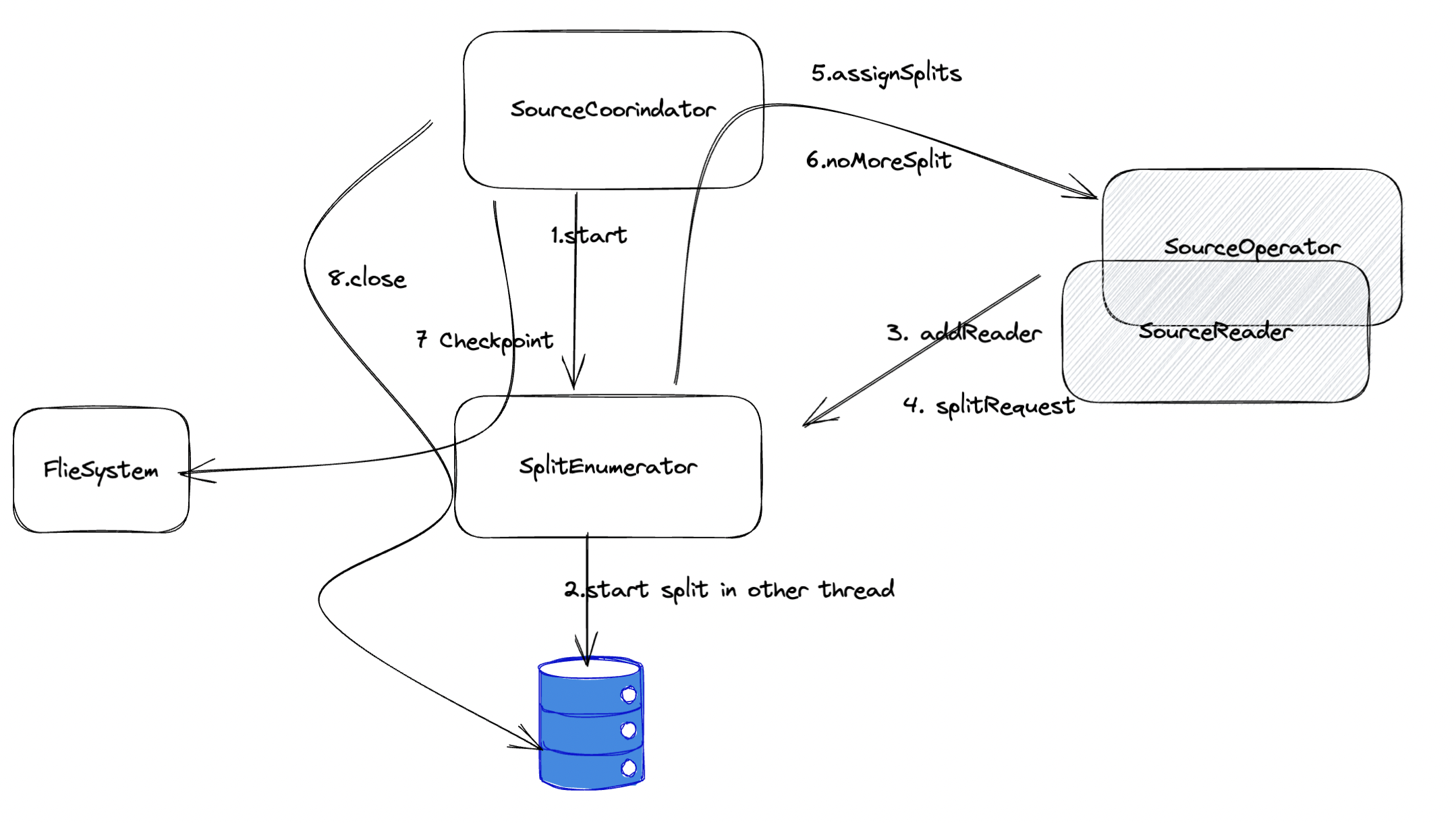
- 【初始化】
SourceCoordinator发起start()方法的调用,此时创建SplitEnumerator并调用SplitEnumerator#start。该方法不应阻塞,调用线程是coordinator线程 - 【启动切片线程】
SplitEnumerator在start中通过启动额外线程来进行数据源逻辑切分操作,形成切片。 - 【接收 Reader】
SplitEnumerator通过addReader接收到准备好能发送的SourceReader - 【与 Reader 进行交互】还能通过其他的方法与 SourceReader 进行交互
SourceReader通过context#sendSplitRequest()的请求切片发送会被SplitEnumerator#handleSplitRequest接收到SourceReader处理失败的split会通过addSplitsBack方法接受到handleSourceEvent还能接受到context#sendSourceEventToCoordinator发送过来的SourceEvent
- 【下发切片】
SplitEnumerator预期会在某些操作(主动通过自身线程驱动,或者被动等待 Source 要求获取 Split)的触发下通过context#assignSplits下发切片到 SourceReader 中 - 【完成切片】如果没有更多的切片则调用
context#signalNoMoreSplits - 【存储 Snapshot】在
CheckpointBarrier到来之后会调用snapshotState生成CheckpointT序列化并存储。 - 【结束】最终生命周期结束后被调用
close方法SourceCoordinator 是串联起 Source 与外部交互的重要的协调者,是实现了
OperatorCoordinator的接口,运行在 JobManager 上负责管理 Source 算子的角色。
所有的OperatorCoordinator均是被 Job Manager 的主线程(mailbox thread)调用,即意味着这些方法均不能出现阻塞操作(IO等操作)。如果涉及到一些阻塞性操作,需要通过context中的方法比如callAsync
在 SourceReader 的调用过程中**SourceOperator**是一个重要的角色,它的顶层父类是StreamOperator,是任务执行过程中实际处理类,上层由StreamTask调用,下层调用 UserFunction。生命周期:open->finish->close。在 SourceOperator 中,会初始化 SourceReader,并赋予context,然后将 reader 的信息发送(operatorEventGateway.sendEventToCoordinator)给SourceCoordinator到SplitEnumerator中之后,调用 reader 的start接口。
预期实现方式-主动线程
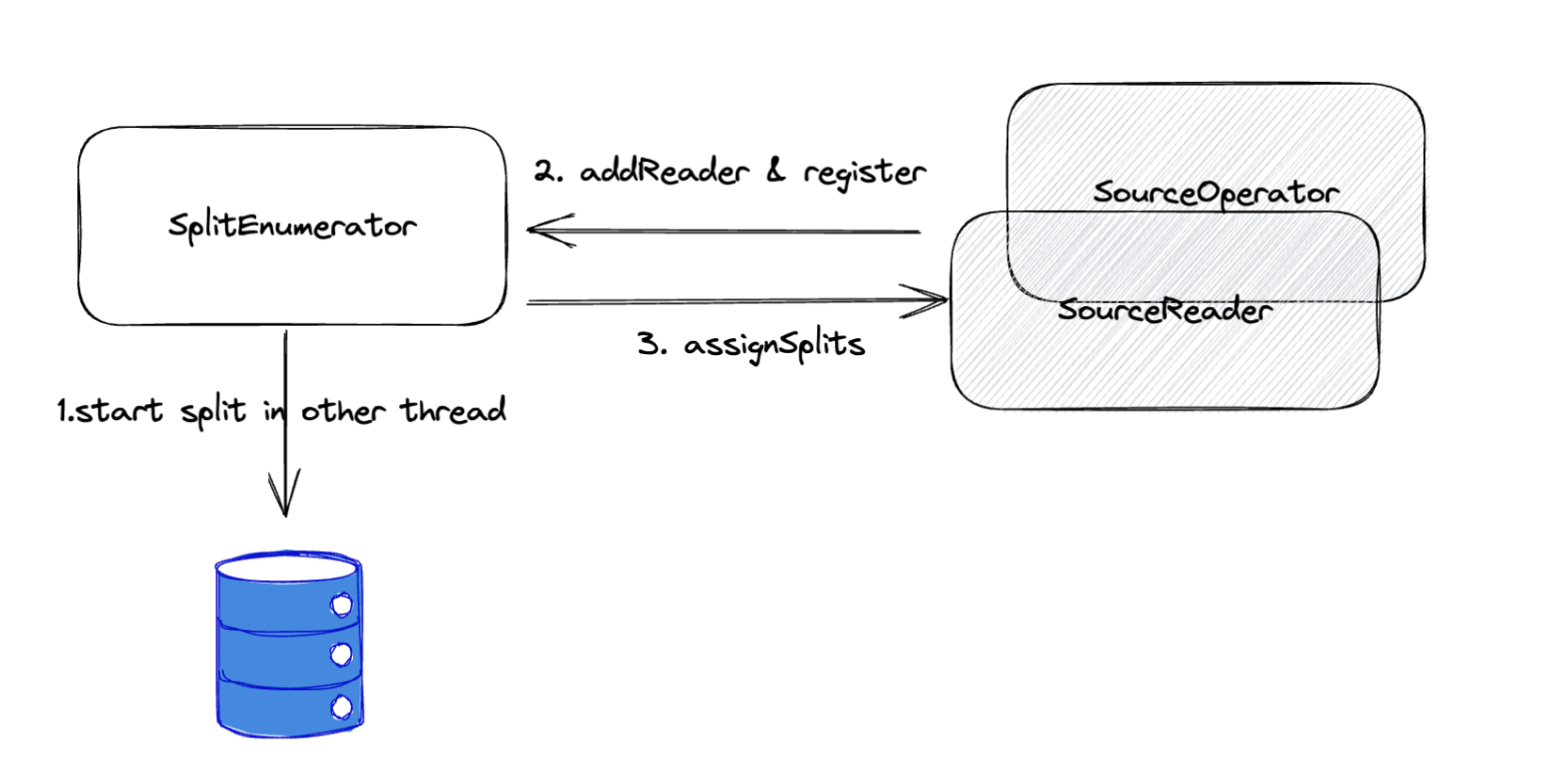
- 通过一个单独的线程(组)来获取切片,然后存储在内存中
- 接收 SourcerReader 并将其注册到内存中
- 通过一个线程不断像内存中的 Split assign 到 Reader 中
多数情况下用在切分切片还是一个 IO 操作比较复杂的情况下进行。
预期实现方式-Lazy 型
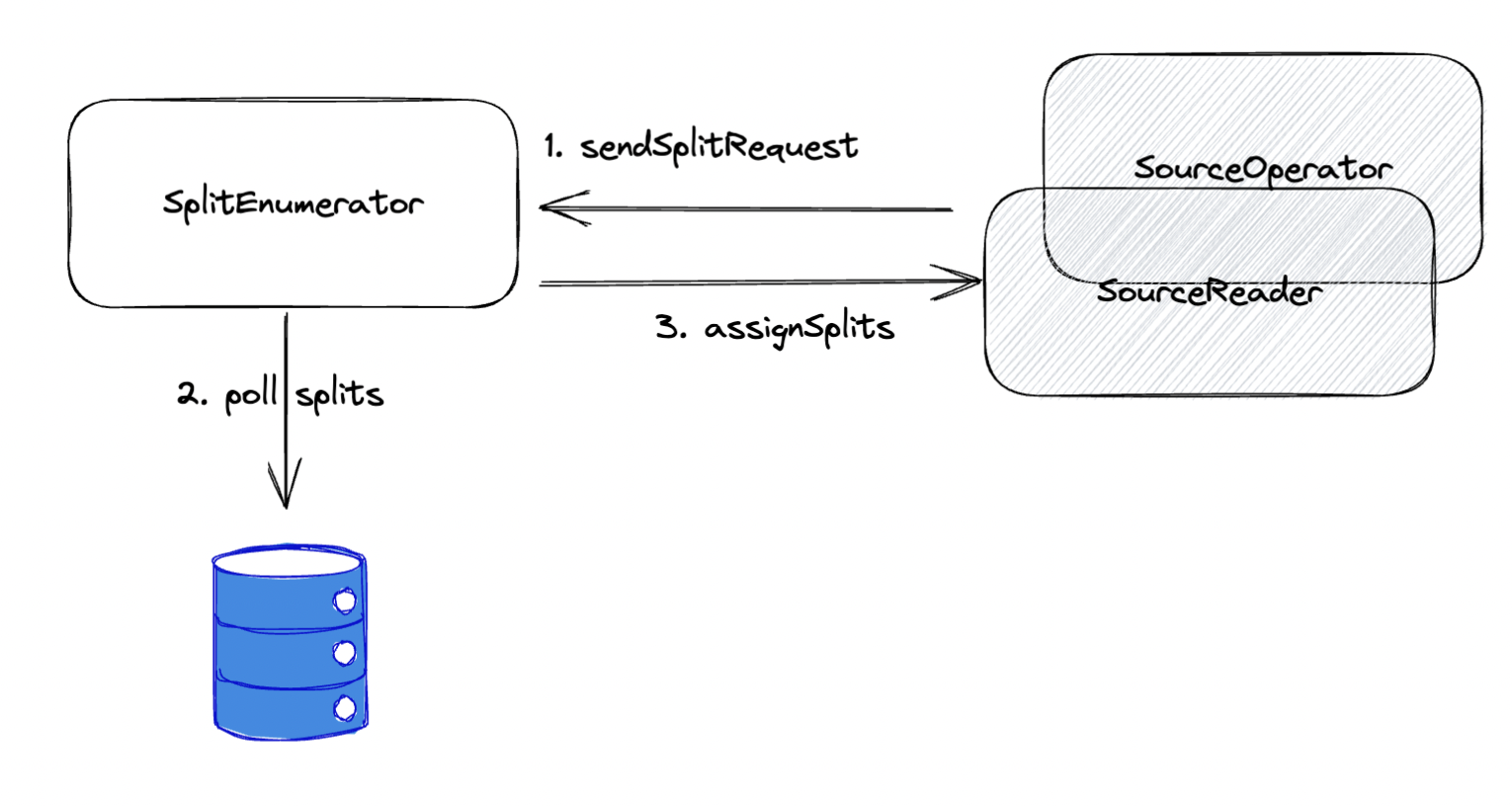
- SourceReader 主动发送
sendSplitRequest请求 Split - 此时 SplitEnumerator 开始组装切片
- 发送到 SourceReader 中
多数情况下用在切分切片只是一个简单分配动作,不涉及阻塞性操作情况下进行。
典型实现概述
- KafkaSourceEnumerator
- 启动(start)之后通过线程(callAsync)监听 kafka 队列和 topic 变化,为每个 Split 通过 reader number 预分配。
- SourceReader 注册到 Enumerator 中,在 context 中;在注册的试试如果存在未分配的 Split 会首先分配到新注册 SourceReader 中。
- 如果存在 topic / partition 变化也会向注册的 Reader 中进行主动分配。
- MySqlSourceEnumerator
- 全量会开启切片线程,通过
context#callAsync间隔向注册的 Reader 发送切片 - 增量就是开始的时候会发送
sendSplitRequest请求的时候获取切片(直接构建)
- 全量会开启切片线程,通过
- StaticFileSplitEnumerator
- Reader 开始的时候会发送
sendSplitRequest,在当前切片结束的时候也会发生sendSplitRequest - SplitEnumerator 会配置 Split 发送到 Reader
- Reader 开始的时候会发送
SourceReaderBase
流程图
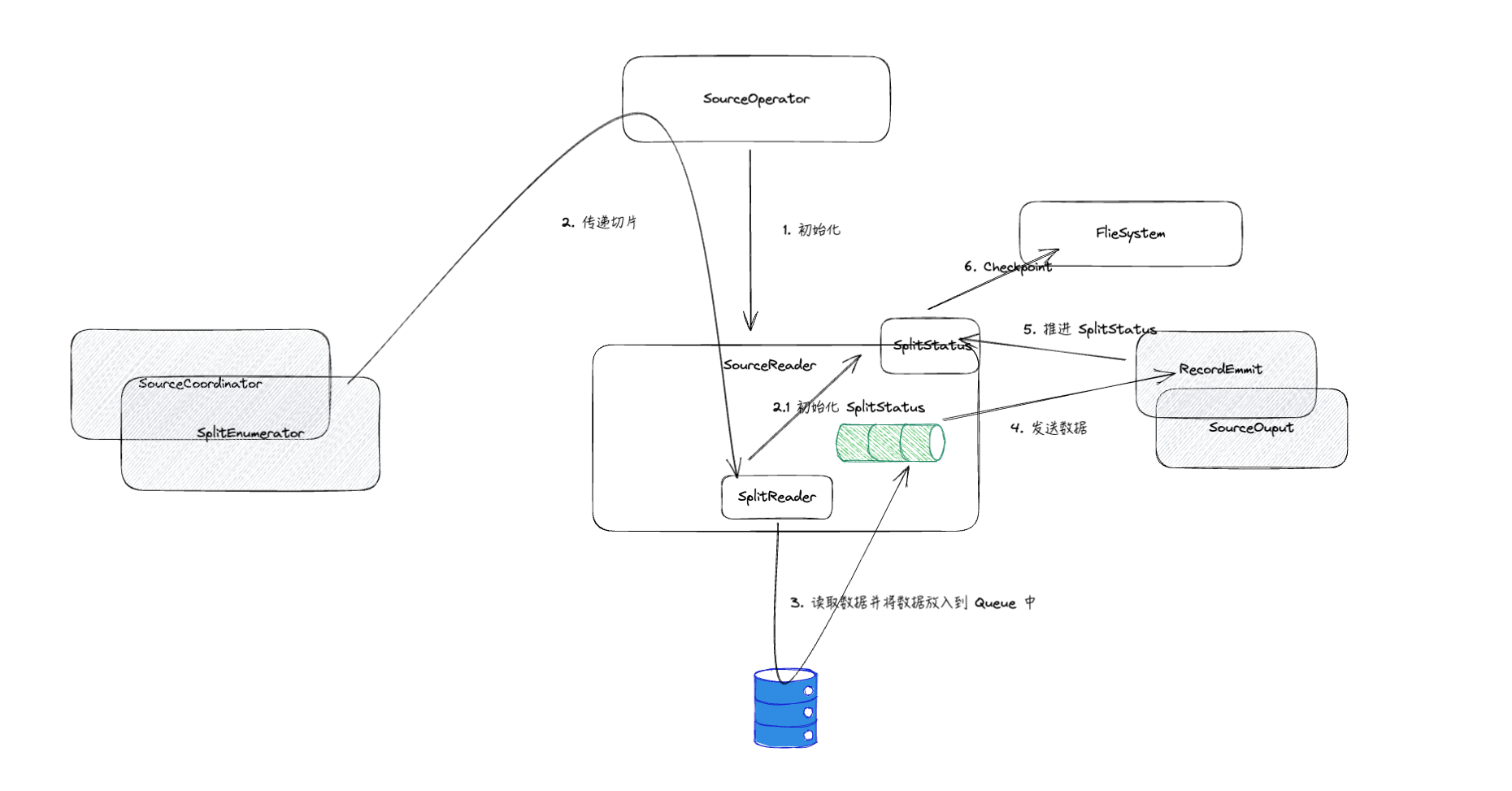
【初始化】SourceOperator 在
open的时候会对 Reader 进行初始化,并执行start方法【接收 Split】当 SplitEnumerator 通过 SourceCoordinator 发送 Split 到 SourceOperator 之后通过
SourceReader#addSplits方法将切片一直传递到SplitReader中。- 切片新增的时候会生成对应的
SplitStatus
- 切片新增的时候会生成对应的
【读取消息】SourceOperator 在
emitNext的时候开始调用读取数据逻辑,此时会触发pollNext方法。在 SourceReader 整个流程中会维护一个FutureCompletingBlockingQueue,通过pollNext方法驱动SplitFetcherManager中管理的线程进而驱动SplitReader读取数据,将数据放入FutureCompletingBlockingQueue供pollNext读取到是整个SourceReader的工作主要流程。读取消息的同时也会查看是否还有多余的消息,如果没有就可以退出了。emitNext是PushingAsyncDataInput接口定义的方法,主要用于处理异步数据源的输入。这个接口的设计目的是支持那些数据生产速度可能与数据处理速度不完全同步的情景,比如从远程服务拉取数据或者处理延时数据源。通过异步方式处理数据可以提高整体系统的吞吐量和效率。【发送消息到下游】得到消息之后通过
RecordEmitter#collect方法将消息发送到下一个节点,并且推进SplitStatus状态更新,同时还会触发 watermark 的推进(如果设置了)- 【切片消息读取完成】会触发
onSplitFinished方法
- 【切片消息读取完成】会触发
【接收到切片完结】
SourceReader#notifyNoMoreSplits被触发更改标记变量noMoreSplitsAssignment=true【snapshot】当 CheckpointBarrier 触发之后,会触发
SourceReader#snapshotState方法,将SplitStatus转换为Split,这里实际是期望Split的范围更小,通过Split序列化器进行存储,后面根据Split进行恢复。
线程模型
SplitFetcherManager 流程分析
SplitFetcherManager 核心就做了两件事:
- 接收切片
- 读取切片数据将数据放入通信队列中
在 SplitFetcherManager 的流程体系中有以下主要角色:
- SplitReader:接收切片与读取切片的实现类
- executors:运行 SplitFetcher 的线程池
- elementsQueue:消息的传输队列
- SplitFetcher:主要核心类,承担了驱动两类任务的职责:
- FetchTask:调用 SplitReader 抓取数据放入 elementsQueue 中
- AddSplitsTask:将 Split 放入 SplitReader 中
主要流程说明: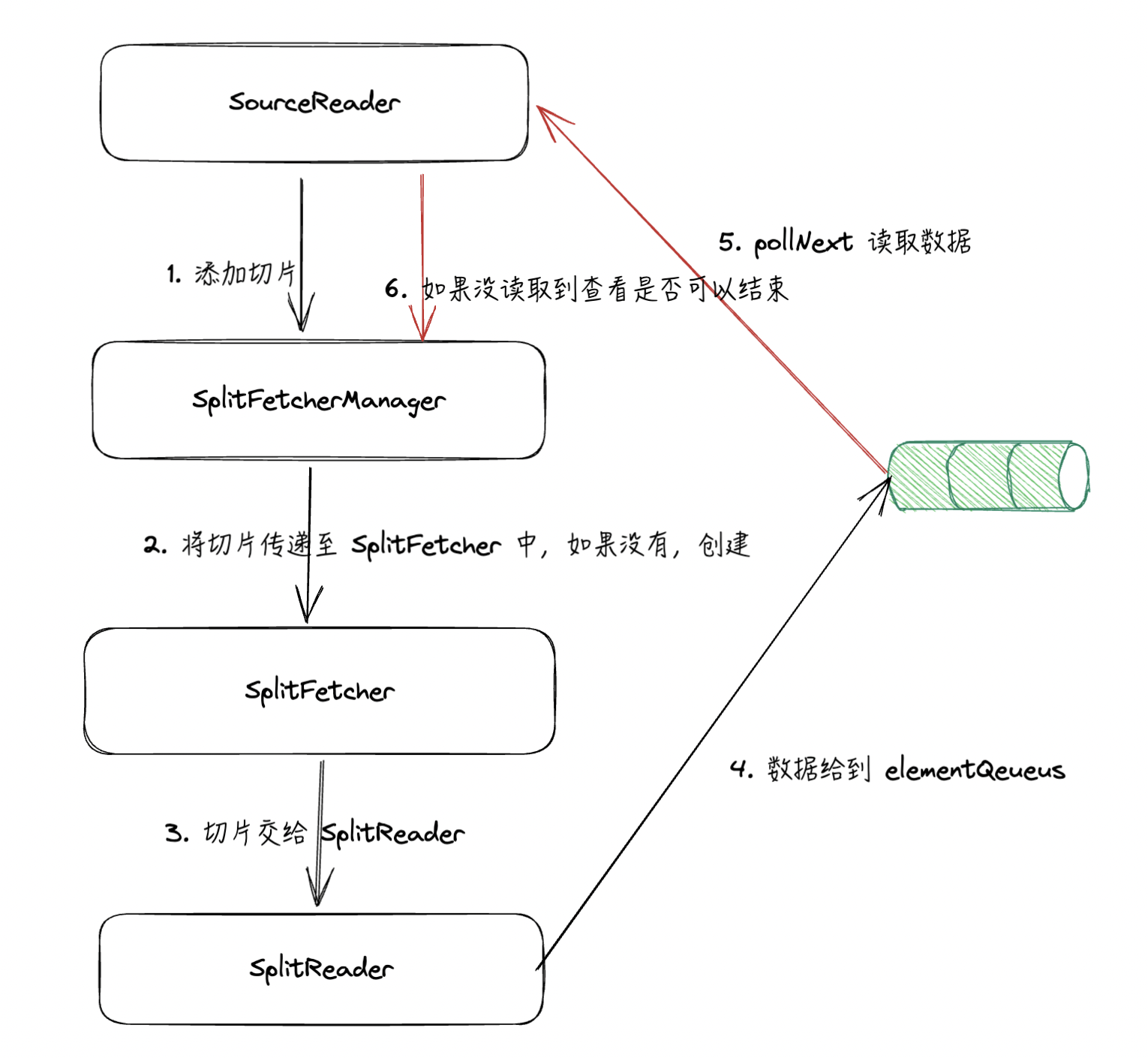
- 加入切片:当 SourceReader 接收到切片之后,会调用
SplitFetcherManager#addSplits方法,这里的方法是抽象方法,预期会调用SplitFetcher#addSplits将Splits加入到SplitReader中 - 运行读取数据的线程:当一个新的
SplitFetcher被创建(createSplitFetcher)的时候,会创建一个新的SplitReader,将elementsQueue也加入其中作为通信队列。通过线程运行 SplitFetcher。 - 查看是否可以结束:SourceReader 的 pollNext 在拉取数据的同时,如果数据不存在,会通过 SplitFetcherManager 的
maybeShutdownFinishedFetchers方法确定 Fetcher 是不是均完成了,可以退出了。条件是:所有 SplitFetcher 中任务队列和为空(没有切片了)&& 已分配的切片已完成
SplitFetcher 流程说明:
SplitFetcher 是根据 closed 标识来判断是否需要退出的,实际是一个循环执行任务的架构,关键任务就是外部传入的 SplitFetcherTask 与自身拉取数据的 FetchTask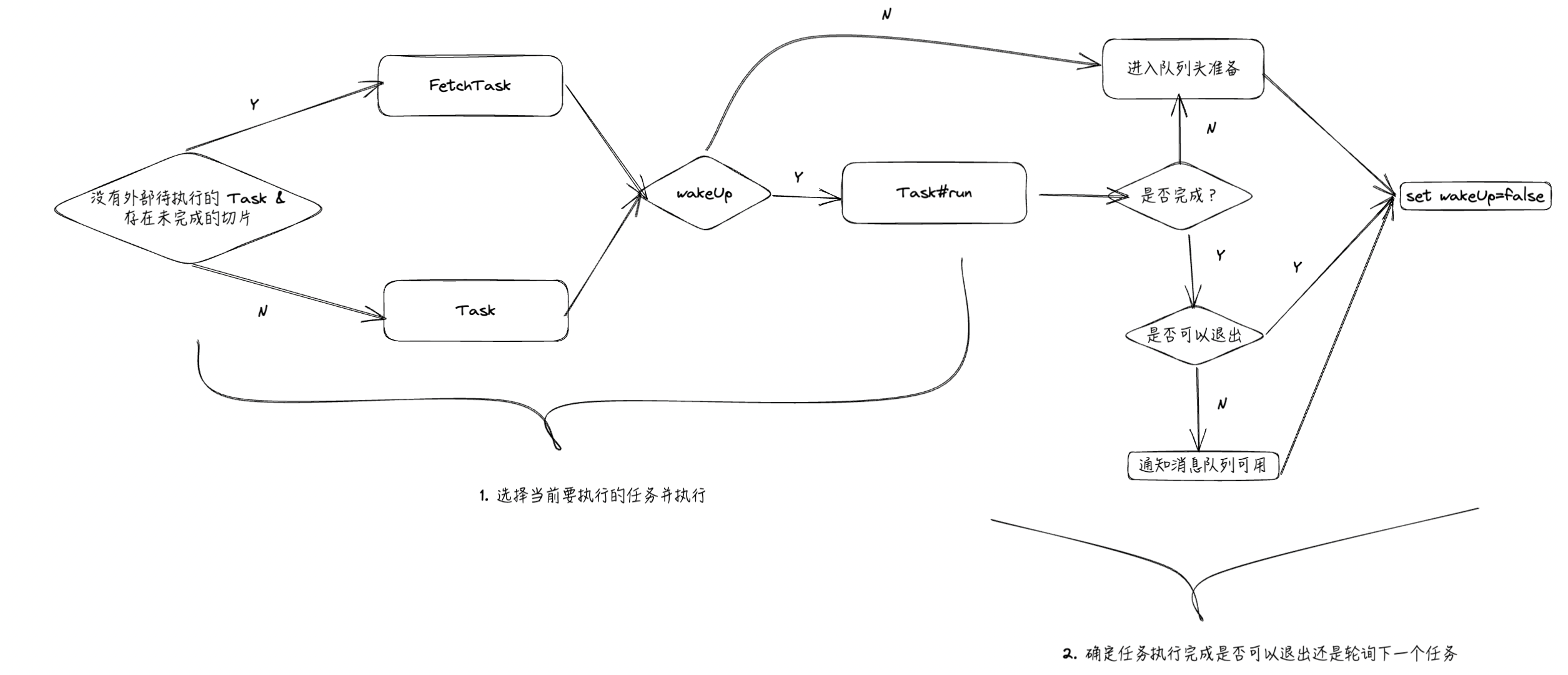
如果不自己扩展 SplitFetcherTask 则常见的 SplitFetcherTask 有以下三个:
- FetchTask:抓取数据任务,下面要重点介绍
- AddSplitsTask:向 SplitReader 添加 Split 的任务
- DummySplitFetcherTask:哨兵,来控制 wakeUp 的流程
接下来介绍 wakeUp 流程与用途:
SplitFetcher、SplitFetcherTask 与 SplitReader 通过 wakeUp 机制来配合,主要是考虑 SplitFetcherTask 在运行过程中要如何去唤醒任务,让其暂停然后执行其他的流程(比如添加切片与停止任务)。这个逻辑是保证添加切片任务能尽早运行并且保证添加切片是非阻塞的操作(加切片的任务线程不能被阻塞,否则其他框架中流转的 Event 就会被阻塞)。
这个流程的保证主要是在:
- SplitFetcher 中主要是:
- 阻塞任务的运行
- [shutdown 时候使用]队列中添加 DummySplitFetcherTask 哨兵,阻塞为执行成功的任务进行待执行队列中
- 调用 SplitFetcherTask 的 wakeUp,在 FetchTask 中的体现是:
- 先让当前的 run 任务中断(通过 run 过程中的标识)
- 没有消息的话,让 SplitReader 停止拉取消息(需要实现 SplitReader#wakeUp 方法)
- 有消息的则是配合
elementsQueue#wakeUpPuttingThread通过 Condition 来阻塞对应 SplitFetcher 线程向elementsQueue投递消息
FetchTask 流程
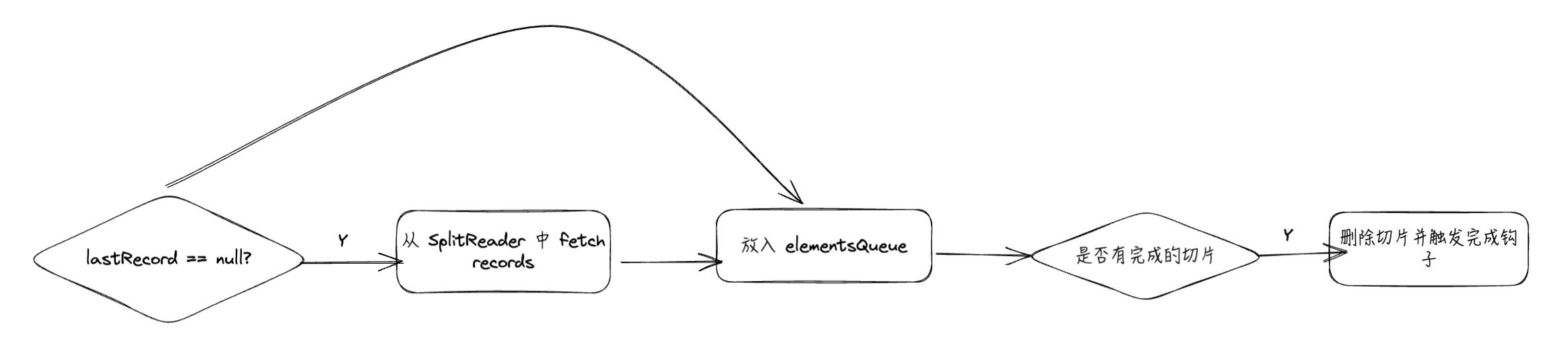
- 如果不存在消息,向 SplitReader 获取消息(必须阻塞获取到)
- 得到消息之后将其放入 elementsQueue 中(之所以有判断 lastRecords 是否为空是因为 wakeUp 流程存在)
- 如果存在已经完成的切片,将已完成的切片从待处理切片中删除,并触发完成钩子(默认忽略)
退出条件

- 切片如果还持续存在,则 SplitFetcher 就不会退出,Flink 任务还会继续
- 如果 SourceReader 中不存在切片了,SplitFetcher 会退出(
SplitFetcher#maybeShutdownFinishedFetchers) ,但是只要noMoreSplitsAssignment没有被下发,那下个切片过来之后 SplitFetcher 又会开始重新启动。 - 当
SplitFetcher都结束并且noMoreSplitsAssignment下发之后还会查看elementsQueue是不是空的,空了后检查是不是因为异常退出,如果不是就正常退出,如果是就抛出异常。
对于 SplitReader 的实现总结
SplitReader 可以说是整个 SourceReaderBase 的核心类,所有的读取数据实现都会汇聚到此。
SplitReader 是在单线程运行的
在 SplitReader 中一定是先调用了 addSplits() 才调用的 fetch() 方法,即在 fetch 方法中一定能获取 split,如果获取不到,一定可以认为是实现方式的问题。
fetch() 的实现要求
- 接口必须返回数据,不能返回 null
- 实现必须响应 wakeUp 方法,哪怕这次没有读取成功,也可以返回以空消息
- 接口返回的 RecordsWithSplitIds 中关键在于,调用逻辑可以结合调用时序图与下面文字说明了解

nextRecord:返回能处理的消息,这个消息会被传入到框架中,如果返回 null,则会读取 nextSplit() 接口,nextSplit 是用于用来维护后面读取 record 的 SplitStatus 的nextSplit:返回下一个要读取的切片,之前说到了在 SplitFetcher 中仅保证了 fetch 的调用次数与 split 次数相同,但是调用 fetch 的时候可能 nextSplit 还不存在,所以这个接口是可以返回 null 的。返回 null 的情况就是会调用finishedSplits来进行操作,不返回 null 的情况也就是使用不会继续将切片返还给 SplitReader,所以 nextSplit 仅是读取切片,而不是读取消息,不能删除保留在 SplitReader 的 nextSplitfinishedSplits:返回这次RecordsWithSplitIds在nextRecord与nextSplit均完成(返回 null)之后结束的切片,有两段操作用到这个信息:RecordsWithSplitIds返回之后立即清理 SplitFetcher 中assignedSplits,这个是判断是否还能调用 fetch() 方法的重要逻辑,如果没及时清理可能会导致 fetch 比 split 的调用数量还多。**不能少传 ****finishedSplits**否则可能导致拉取不到切片。- 在
nextSplit返回 null 之后会将 SplitStatus 从 SourceReaderBase 中删除并标记为已完成。不能多传 finishedSplits 否则可能导致没有找到 SplitStatus 的 NEP。
SingleThreadFetcherManager 流程分析
介绍完 SplitFetcherManager 之后对于 SingleThreadFetcherManager 之后就简单了,就一个逻辑
- 当前没有 SplitFetcher,创建一个,加入切片,启动
- 如果已经存在了 SplitFetcher,用已有的 SplitFetcher 加入切片
正因为只有一个 SplitFetcher 线程在运行,所以 SingleThread,如果阻塞点主要是数据源 IO 操作,并且无法通过并发来提高读取效率,那这种方式是最友好的方式(比如消息队列等数据源情况就很明显)。
实现多线程读取 Split 模型
在实现自己的 SplitFetcherManager 的时候,需要注意的是在实现 addSplits的方法中,要确定怎么创建 SplitFetcher,需要记住的是,由于 pollNext 随时在检测 SplitFetcher 是否空闲,如果空闲就会停止线程,所以需要先将 Split 加入 SplitFetcher 之后才能启动 SplitFetcher。
控制你的 SplitFetcherManager 产生多少了 SplitFetcher 就是其线程模式的实现。具体实现我们在后面实现自己的 Flink Connector Source 的时候会详解。
总结
本文描述了 SourceReaderBase 的主要关键流程,尤其对其中线程模型的做了充分描述。
在下一篇文章中我将对 Kafka-Source 的实现进行详细说明,以对照本篇文章的 Base 实现叙述。