FLIP-144: Native Kubernetes HA for Flink
本文是基于 FLIP-144 的笔记作品,主要描述 Flink HA 基于 Kubernetes 的设计思路
为什么区别于 ZK HA 还需要有 K8S 的模式?
避免在 K8S 基础上海需要增加 ZK 集群的管理,K8S 已经提供了 leader election and configuration storage(i.e. ConfigMap)。
有哪些 HA 组件,分别有啥用途?
在 HighAvaiablilityServices 中需要针对 5 个 components 进行抽象。
- LeaderElectionService:针对 ResourceManager, Dispatcher, JobManager, RestEndpoint 来通过 LeaderElectionService 来竞选 Leader。完成选举之后 leader 的地址信息会被存入 ConfigMap 中。
- LeaderRetrievalService:
- 用于 Client 获取 RestEndpoint 地址
- 用于 JobManager 获取注册需要的 ResourceManager 地址
- 用于 TaskManager 获取对应 LeaderElectionService 地址(比如 JobManager 与 ResourceManager),以便于进行 registry 和提供 slot
- RunningJobsRegistry:注册运行时的 Job 信息,当出现故障恢复时候将注册表中的 Job 信息恢复
- SubmittedJobGraphStore:运行中 JobManager 的 JobGraph 实例。仅元信息(location reference, DFS path)存储在 ConfigMap 中,实际的数据存储在 DFS 中。
- CheckpointRecoveryFactory:
- 存储 checkpoint 恢复需要的元信息到 ConfigMap 中
- 存储最近 Checkpointer counter
基于 ResourceVersion(k8s) 比较 k8s 对象前后关系,选举方式如下:
- 启动多个 JobManager 实例,首先创建了 ConfigMap 的实例将会成为 leader,并将 leader 信息添加到其他 follow 中的 annotation(control-plane.alpha.kubernetes.io/leader) 中。
- Leader-JobManager 定期更新租约(lease)以确保存活。
- 如果更新时间超过 duration 则意味着 Leader 下线。其他 Follow 会通过检查 ConfigMap 获知该信息,然后开始新 Leader 的选举,直到 Follow 成功更新带有自己的 identity 和租约期限(lease duration)时新 Leader 诞生。
注意点:
- 基于 k8s 的限制,ConfigMap 的信息不能大于 1MB,所以仅 dfs location reference 在 ConfigMap 中,实际数据存储在 DFS(high-availability.storageDir) 中。job graphs, completed checkpoints, checkpoint counters, running job registry 也在 ConfigMap 中。
- 通过 Kubernetes Resource Version 自增方式以乐观锁的形式来保证 read/update/write 的原子性。工作方式 CAS。确保 Flink 状态元数据不会并发更改。
- flink 集群中的 ConfigMap、Service、TaskManagerPod 的 owner 均是 JobManager Deployment,如果 JobManager Deployment 被销毁,则对应资源也会销毁。
- ConfigMap 是一个扁平架构,与 zk 层次性存储架构不同。所以存储的时候每个组件都有各自的 ConfigMap。
架构
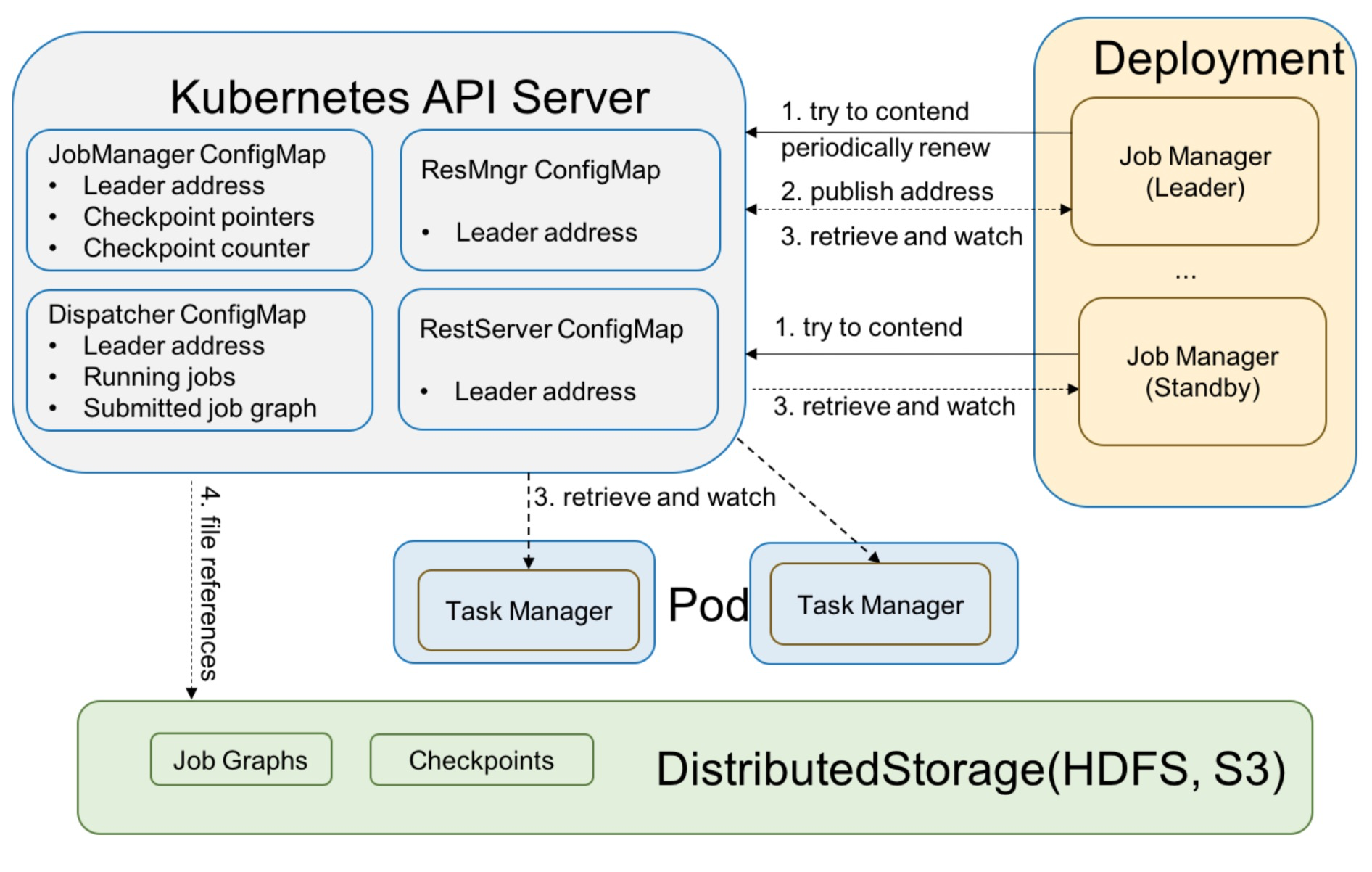
- 对于 Leader 选举,有一组候选 JobManagers 会参与竞选,其中某个 JobManager 选举成功,Leader-JobManager 会通过 Heatbeat 来更新自己 Leader 的位置(position)。其他所有 JobManagers 会周期性尝试选举,确保 JobManager 出现问题能快速切换。ResourceManager、JobManager、Dispatcher、RestEndpoint 都有各自的 Leader 选举服务和 ConfigMaps。
- 活跃的 Leader 会在 ConfigMap 更新自己的地址(address),需要注意的是,我们使用相同的 ConfigMap 来竞争锁并存储 Leader address。
- LeaderRetrievalService 被用于查找活跃的 Leader address 并且注册自身。For Example,TaskManagers 会检索 ResourceManager 和 JobManager 来注册并提供 slot。我们会在 LeaderRetrievalService 中使用 Kubernetes Watcher,一旦 ConfigMap 内容变化,通常意味着 Leader 变更,需要获取最新 Leader 的地址。
- 其他所有元信息(running jobs, job graphs, completed checkpoints and checkpointer counter) 会直接存储在不同的 ConfigMap 中,只有 Flink 集群达到全局结束态的时候才会清理。
实现-LeaderElection
当前通过内嵌 Flink 中的 fabric8 kubernetes client 来支持的。实现类 KubernetesLeaderElector。通过 ClusterId - Component 来作为 ConfigMap 的名称,该创建逻辑是 Block 的。
实现-LeaderRetrieval
实现类通过 DefaultLeaderRetrievalService包装 KubernetesLeaderRetrievalDriver使用 KubernetesConfigMapSharedWatcher来监控 ConfigMap 实现。
在这里 KubernetesSharedInformer的实现作为一个 Watcher 的 Abstract 实现,通过 watch 方法将监听与事件处理通过回调(FlinkKubeClient.WatchCallbackHandler
结束并清理数据
当 Flink 集群达到结束状态(FAILED、CANCELED、FINISHED)时,所有高可用数据都将在 HighAvailabilityServices#closeAndCleanupAllData逻辑中被清理,对于 K8S 也相同。
下面命令仅会关闭 Flink Session Cluster 而保留 HA 相关的 ConfigMap
1 | echo 'stop' | ./bin/kubernetes-session.sh -Dkubernetes.cluster-id=<ClusterId> -Dexecution.attached=true |
下面命令会取消现在 session or application 模式下的 job 并且删除 HA 数据
1 | # Cancel a Flink job in the existing session |
如果用户想保留 HA 数据,则可以通过 kubectl delete deploy <ClusterId>,Flink 资源将会被销毁,但是 HA 相关的 ConfigMap 将会保留(因为没有设置 owner),后面可以通过 kubernetes-session.sh/ flink run-application 再次启动 cluster 使用之前的 ConfigMap。
使用方式-Standalone on K8S
1 | apiVersion: v1 |
使用方式-Native K8S
1 | ./bin/flink run-application -p 10 -t kubernetes-application -Dkubernetes.cluster-id=k8s-ha-app1 \ |