Java并发基础-线程
线程
线程使用方式通常是继承Thread类或实现 Runnable接口的方式来创建使用的。
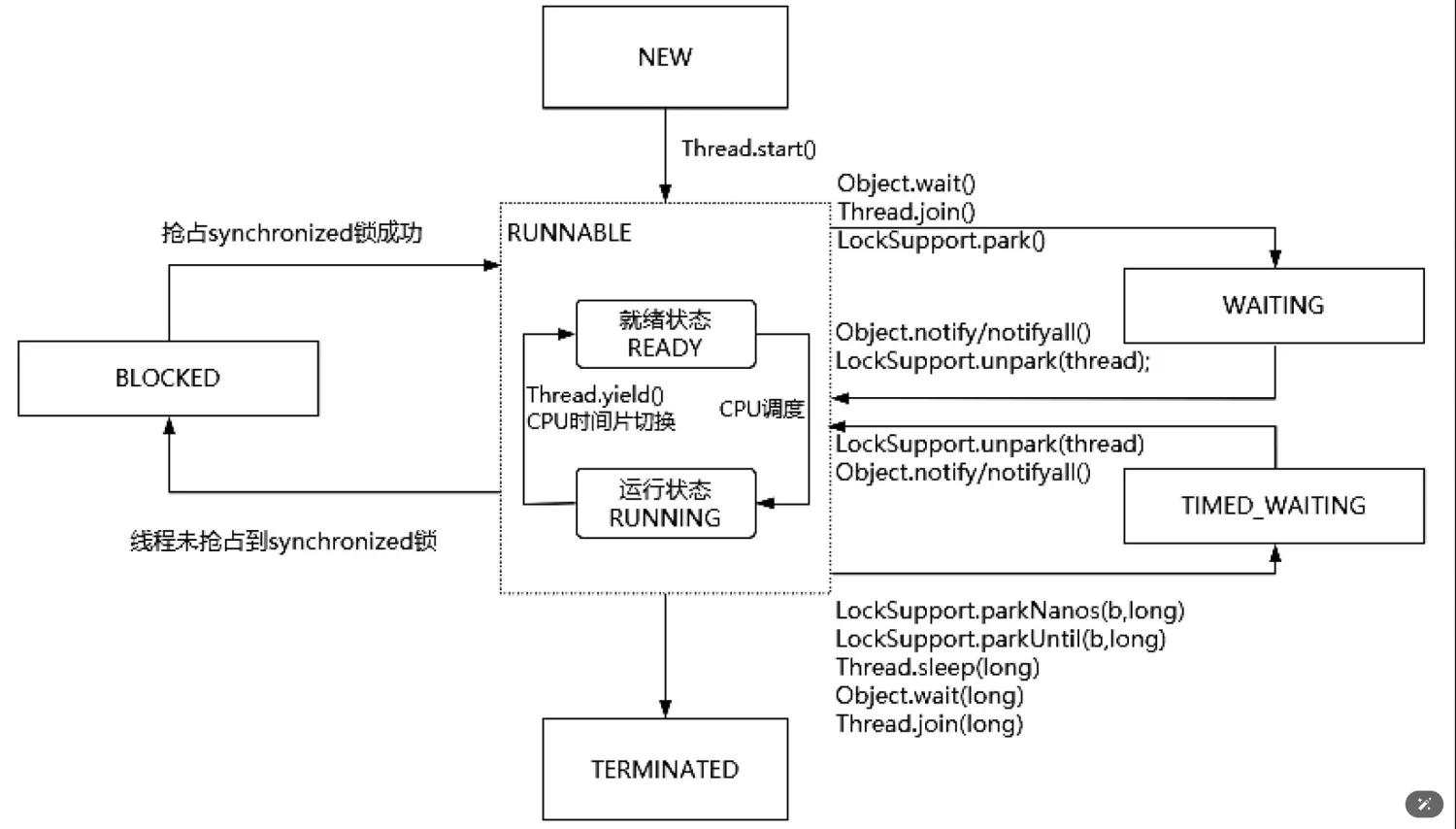
线程的状态与流转方式
Java 线程共有 6 种状态 :
**NEW(新建) **:线程对象已创建但未调用 start()。
RUNNABLE(运行/就绪) :线程正在运行或等待 CPU 调度。
**BLOCKED(阻塞) **:线程因等待锁(如 synchronized)进入阻塞状态 。
WAITING(无限等待) :线程调用 wait()、join() 等方法进入等待状态,需其他线程显式唤醒 。
TIMED_WAITING(定时等待) :线程调用 sleep(long)、wait(long) 等方法进入定时等待 。
TERMINATED(终止) :线程任务执行完毕或抛出异常结束 。
中断线程
stop()方法行为
- 立即抛出ThreadDeath异常,在run()方法中任何一个执行指令都可能抛出ThreadDeath异常。
- 会释放当前线程所持有的所有的锁,这种锁的释放是不可控的。可能使得原本原子性的操作不具备原子性了。
所以 stop 方法并不是一个推荐的行为。
interrupt() 方法行为
interrupt() 并不会直接强制终止线程,而是通过设置线程的中断状态(isInterrupted)为 true,向目标线程发送中断请求。若线程处于阻塞状态(如调用 sleep()、wait()、join() 等方法),则会抛出 InterruptedException,从而唤醒线程。
- 阻塞场景 :interrupt() 能有效中断线程的阻塞状态(如等待、睡眠),这是其主要设计目的 。
- 非阻塞场景 :若线程未被阻塞,interrupt() 仅设置中断标志,需线程主动通过 isInterrupted() 或 Thread.interrupted() 检测该标志并退出运行逻辑。例如,在循环中定期检查中断状态
- 无法中断 I/O 阻塞 :对于某些 I/O 阻塞(如 InputStream.read()),interrupt() 可能无效,需结合其他机制处理 。
1 | // 循环检测 |
在 JVM 源码层面,interrupt() 通过本地方法(Native Method)修改线程状态,并触发对阻塞操作的中断检查。
线程开销
内存消耗
主要由线程栈和线程本地存储(Thread Local Storage)组成,具体消耗取决于 JVM 配置及线程状态:
线程栈内存
默认情况下,Java 线程栈的大小由 JVM 参数 -Xss 控制。在 JDK 1.4 中,默认值为 256KB ,而现代 JVM(如 Java 8)中默认值可能为 1MB 。通过 -Xss 可显式调整此值,例如 -Xss512k 表示每个线程栈占用 512KB 虚拟内存。需要注意的是,线程栈分配的是虚拟内存 ,实际物理内存(提交内存)按需分配,例如空闲线程栈可能仅占用约 10~20KB 的物理内存 。
线程本地存储(TLS)
线程本地存储用于保存线程私有数据(如 ThreadLocal 变量),其内存消耗取决于具体存储的数据量。这部分内存独立于线程栈,直接占用堆外内存或堆内存 。
实际内存占用示例
若线程栈默认为 1MB,1000 个线程理论上需约 1GB 虚拟内存,但实际物理内存可能远小于该值(如实验中观察到 1000 个空线程仅占用约 10MB 物理内存)。
对于活跃线程较多的场景(如 14,000 个线程),声明的栈内存总和可能高达 14GB 以上,但实际提交的物理内存约为 13.71GB,说明虚拟内存与物理内存的使用存在差异 。
影响因素
- **线程阻塞状态 **:阻塞线程可能因未使用完整栈空间而减少物理内存占用。
- JVM 参数优化 :减小 -Xss 值(如设为 256KB)可显著降低线程栈内存消耗 。
- **并发模型 **:大量线程(如 100 万)可能导致内存占用激增(约 250MB 以上),需结合异步/协程模型优化
上下文切换
在多任务操作系统中,为了提高CPU的利用率,可以让当前系统运行远多于CPU核数的线程。但是由于同时运行的线程数是由CPU核数来决定的,所以为了支持更多线程运行,CPU会把自己的时间片轮流分配给其他线程,这个过程就是上下文切换。
导致线程上下文切换的原因总结如下
- 多个任务抢占synchronized同步锁资源
- 在线程运行过程中存在I/O阻塞,CPU调度器会切换CPU时间片
- 在线程中通过主动阻塞当前线程的方法释放CPU时间片
- 当前线程执行完成后释放CPU时间片,CPU重新调度
线程上下文切换需要注意两点
- 当两个线程切换属于不同的进程时,由于进程资源不共享,所以线程的切换其实就是进程的切换
- 当两个线程属于同一个进程时,只需要保存线程的上下文
线程的上下文切换,需要保存上一个线程的私有数据、寄存器等数据,这个过程同样会占用CPU资源,当上下文切换过于频繁时,会使得CPU不断进行切换,无法真正去做计算,最终导致性能下降。
如何减少上下文切换呢?
- 减少线程数,同一时刻能够运行的线程数是由CPU核数决定的,创建过多的线程,就会造成CPU时间片的频繁切换
- 采用无锁设计解决线程竞争问题,比如在同步锁场景中,如果存在多线程竞争,那么没抢到锁的线程会被阻塞,这个过程涉及系统调用,而系统调用会产生从用户态到内核态的切换,这个切换过程需要保存上下文信息对性能的影响。如果采用无锁设计就能够解决这类问题
- 采用CAS做自旋操作,它是一种无锁化编程思想,原理是通过循环重试的方式避免线程的阻塞导致的上下文切换。
死锁问题定位
对于死锁问题的排查,具体操作步骤如下:
- 通过 jps 命令,查看Java进程的pid
- 通过
jstack <pid>命令查看线程 dump 日志。当发现死锁时,可以在打印的dump日志中找到Found oneJava-level deadlock:信息,根据信息的内容分析问题出现的
1 | public class DeadlockExample { |
程序行为分析:
- 线程1先获取lockA,随后尝试获取lockB;
- 线程2先获取lockB,随后尝试获取lockA;
- 当两个线程同时执行到各自的第二个synchronized块时,会出现以下情况:
- 线程1持有lockA,等待lockB释放;
- 线程2持有lockB,等待lockA释放;
双方进入永久等待状态,无法继续执行。
死锁原因:
- 资源互斥 :锁对象(lockA/lockB)被一个线程独占;
- 持有并等待 :线程在等待其他锁时未释放已持有锁;
- 不可抢占 :锁只能由持有线程主动释放;
- 循环等待 :线程间形成环形依赖链
CPU 问题定位定位
- 定位高 CPU 占用的 Java 进程
- 使用
top命令查看系统中 CPU 占用最高的进程:
1 | top |
- 按
P键按 CPU 使用率排序,找到目标 Java 进程的 PID(进程 ID)。
- 查看进程内线程的 CPU 占用情况
- 使用
top -Hp <PID>查看该进程中所有线程的 CPU 占用情况:
1 | top -Hp <PID> |
- 找到占用 CPU 最高的线程 ID(TID)。
- 转换线程 ID 为 16 进制
- 将线程 ID(TID)转换为 16 进制格式(用于后续与线程堆栈匹配):
1 | printf "%x\n" <TID> |
- 例如,若 TID 为
1234,转换后为4d2。
- 导出线程堆栈并分析
- 使用
jstack导出 Java 进程的线程堆栈:
1 | jstack <PID> > thread_dump.txt |
- 在
thread_dump.txt中搜索 16 进制的线程 ID(如4d2),找到对应的线程堆栈信息,分析其当前状态和调用栈 。
- 使用 Arthas 快速定位(可选)
- 阿里开源的 Arthas 工具提供了更高效的分析方式:
- 启动 Arthas 并附加到目标进程:
1 | java -jar arthas-boot.jar <PID> |
2. 输入 `thread` 命令,自动列出 CPU 使用率最高的线程及其调用栈 。
- 常见问题场景
- 死循环或频繁 GC:线程堆栈中可能显示循环调用或
GC相关操作 。 - 锁竞争:线程可能卡在
BLOCKED状态,等待某个锁 。 - I/O 或网络阻塞:线程可能长时间处于
WAITING状态 。
- 进一步排查
- 如果线程堆栈无法直接定位问题,可通过以下方式深入分析:
- 使用
jstat检查 GC 频率和耗时 。 - 使用
jmap导出堆内存快照分析内存泄漏 。 - 结合代码日志定位高频操作或异常逻辑 。
- 使用
通过上述步骤,可以快速定位 Java 程序中导致 CPU 过高的具体线程及代码逻辑 。
线程池的使用与参数说明
线程池是为了解决需要重复创建线程以执行某个任务,但是任务执行时间通常不长而产生的。比如 HTTP 请求的处理。
线程池实际上运用的是一种池化技术,所谓池化技术就是提前创建好大量的“资源”保存在某个容器中,在需要使用时,可以直接从该容器中获取对应的资源进行处理,用完之后回收以便下次继续使用。
在Java.Util.Concurrent包中,专门提供了与线程池有关的API,我们可以通过两种方式来创建线程池。
- ThreadPoolExecutor,线程池的具体实现类。
- Executors,提供了一系列工厂方法,用来创建不同类型的线程池,返回的线程池类型为ExecutorService接口。
ThreadPoolExecutor 的参数
corePoolSize(核心线程数)
线程池中始终保留的线程数量,即使这些线程处于空闲状态也不会被回收。
示例:设置核心线程数为 5,表示线程池至少保持 5 个线程可用 。maximumPoolSize(最大线程数)
线程池允许创建的最大线程数。当任务队列已满且当前线程数小于maximumPoolSize时,线程池会创建新线程处理任务。
注意:若maximumPoolSize与corePoolSize相等,则线程池大小固定 。keepAliveTime(空闲线程存活时间)
非核心线程(即超过corePoolSize的线程)在空闲状态下的存活时间。超过该时间未执行任务的非核心线程会被终止并释放资源。
单位通过unit参数指定(如秒、毫秒) 。workQueue(工作队列)
存储等待执行的任务的阻塞队列。常见的实现类包括LinkedBlockingQueue(无界队列)、ArrayBlockingQueue(有界队列)等。
队列容量需根据任务负载合理设置,避免内存溢出或任务拒绝 。threadFactory(线程工厂)
用于创建新线程的工厂类,通常用于设置线程名称、优先级等属性。
建议自定义线程工厂为线程池命名,便于调试和日志追踪 。handler(拒绝策略)
当线程池无法处理新任务(如队列已满且线程数达到maximumPoolSize)时的处理策略。常见策略包括:AbortPolicy(抛出异常,默认)CallerRunsPolicy(由调用线程自行处理)
需根据业务需求选择合适的拒绝策略 。
最佳实践与注意事项
- 合理配置参数
- 根据任务类型(CPU 密集型、I/O 密集型)调整线程数。例如,CPU 密集型任务建议
corePoolSize = CPU 核心数,I/O 密集型任务可适当增大线程数 。 - 避免将
workQueue设置为无界队列(如LinkedBlockingQueue无容量限制),可能导致内存溢出 。
- 根据任务类型(CPU 密集型、I/O 密集型)调整线程数。例如,CPU 密集型任务建议
- 区分业务场景
- 不同类别的业务(如异步日志、定时任务)应使用不同的线程池,避免资源竞争和相互影响 。
- 监控运行状态
- 定期检查线程池的活跃线程数、队列大小等指标,及时调整参数以优化性能 。
- 资源释放
- 使用完线程池后需调用
shutdown()或shutdownNow()关闭线程池,避免资源泄漏 。
- 使用完线程池后需调用
线程池的原理
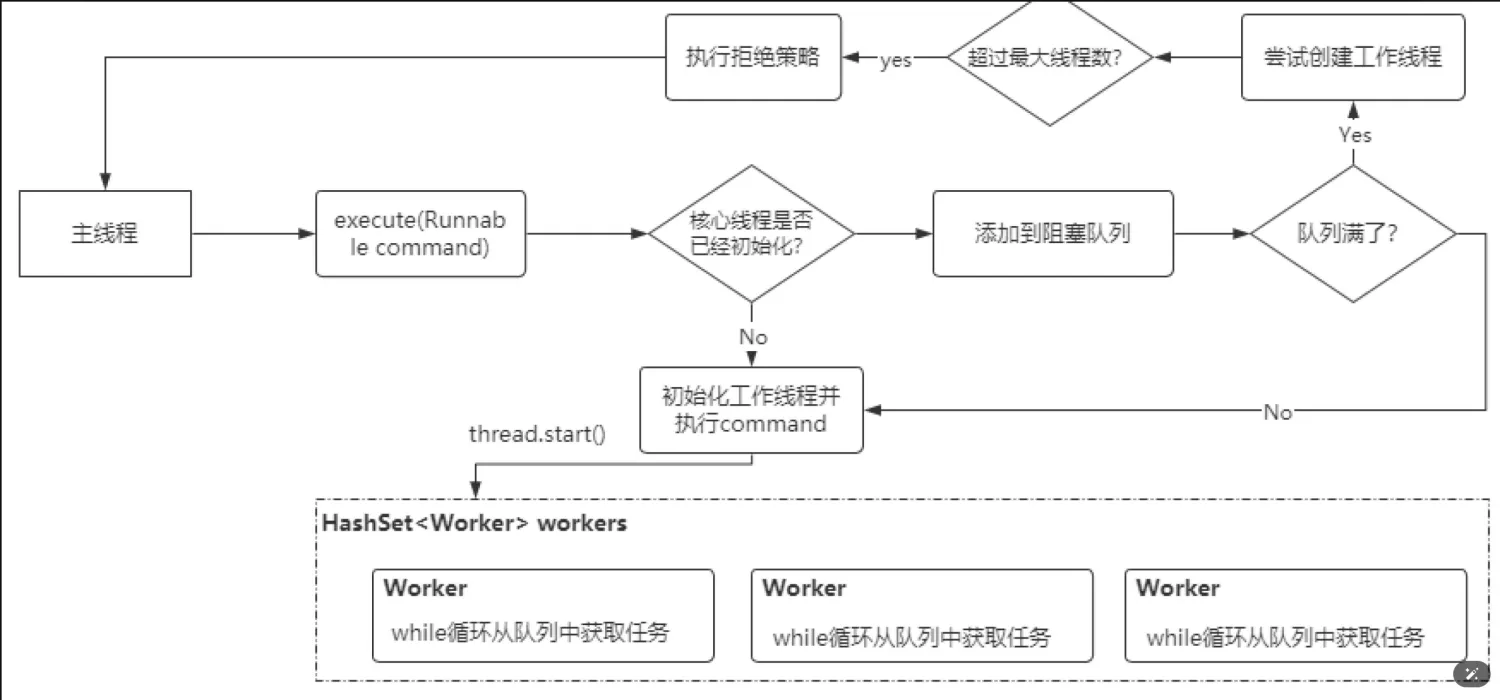
ThreadPoolExecutor线程池的具体实现流程如下:
- 调用
execute(Runnable command)往线程池中提交一个任务后,线程池首先会判断核心线程是否已经初始化(因为线程池默认是被动初始化的,当然在创建线程池的时候可以完成核心线程的初始化,可以通过ThreadPoolExecutor类的构造方法中提供的prestartCoreThread()方法完成),如果核心线程没有初始化,则创建一个工作线程并启动,这个线程启动后会从阻塞队列中获取任务并执行。 - 把 command 任务通过
offer()方法添加到线程池的阻塞队列workQueue中。 - 如果队列满了,则尝试创建非核心工作线程并启动,这些非核心工作线程也会从阻塞队列workQueue中获取任务并执行,相当于提升了线程池的处理能力。
- 如果线程池中总的工作线程数达到阈值,则执行拒绝策略。