Datax 源码阅读
主要概念解释
- Reader:数据采集模块,负责数据读取,将数据发送给 Channel。
- Writer:数据写入模块,负责不断读取 Channel 的数据,并将 Channel 的数据写入到目的端。
- Channel:通过
pushX与pullX接口提供 Plugins 数据通道能力,同时统一统计、限速能力。 - RecordSender:基于 Channel 封装的接口,用于 Reader 将 Record 传递到框架
- RecordReceiver:基于 Channel 封装的接口,用于 Writer 从框架获取 Recrod
- Job:单个数据同步的作业,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job 模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子 Task)、TaskGroup 管理等功能。
- Task:Task 是 DataX 作业的最小单元,每一个 Task 都会负责一部分数据的同步工作。Task 由 TaskGroup 进行管理。Task 会固定启动 Reader -> Channel -> Writer 的线程来进行同步工作。
- TaskGroup:管理一组 Task 的运行。
线程模型
在 DataX 中容易见到 Job、TaskGroup 等实际概念是以 Container 包装成一个个能 start 的实例。
而与线程配合的则是以 Runner封装,包括 TaskGroupContainerRunner、ReaderRunner、WriterRunner
其线程模型如下: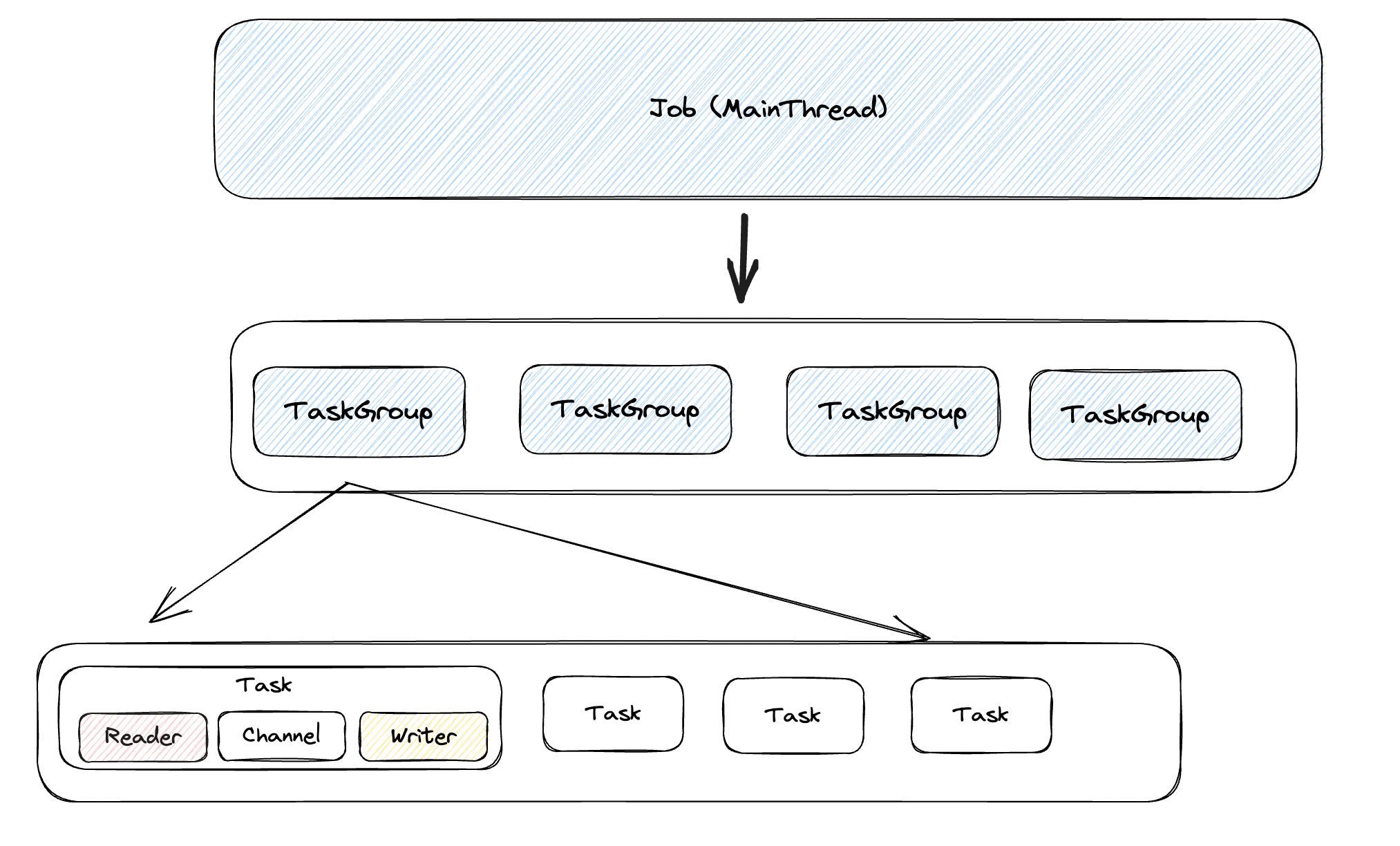
从运行模型来说
Job持有多个TaskGroup并通过FixedThreadPool(size)的形式运行其中的多个Task- 每个
Task将Reader与Writer封装的Thread运行起来,需要注意的是同时运行的数量不允许超过Channel的数量,也就是说虽然概念上TaskGroup封装了多个Task并以Task形式传输数据,但实际上Task仅是一个内部的数据结构,实际运行的线程是ReaderThread与WriterThread,二者依赖自己的接口向Channel传输数据。
Plugin 设计
在 DataX 设计框架中,Plugin 实现者只需要做两件事
- 如何切分任务
- 切分的任务如何读数据
这也映射到需要实现 Reader 与 Writer 的两个类
Reader.Job/Writer.Job:关注根据配置切分任务,后续每个配置会经由框架拆分成等量的Task1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public static class Job extends Reader.Job {
public void init() {
// 此时可以通过super.getPluginJobConf()获取与本插件相关的配置,
// 这里主要是初始化配置项,比如 OB 会初始化是 mysql / oracle 模式
}
public void prepare() {
// 预处理,比如清空目标表等操作
}
public List<Configuration> split(int adviceNumber) {
// 拆分Task。参数 adviceNumber 框架建议的拆分数,
// 一般是运行时所配置的并发度。值返回的是Task的配置列表。
// 这里拆分逻辑还是相当有讲究的。DataX 提供的通用 split 逻辑
// 实际仅查询出来最大最小值,然后根据最大最小值之间的差距直接计算切片逻辑
// 优势是切片逻辑简单,切片时候不需要查询数据
// 缺点也很明显,数据可能不均衡,受数据类型影响非常大
return null;
}
public void post() {
// 全局的后置工作,比如 mysqlwriter 同步完影子表后的 rename 操作。
}
public void destroy() {
// 销毁资源
}
}Reader.Task/Writer.Task:关注获取配置之后怎么读写数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public static class Task extends Reader.Task {
public void init() {
// Task 对象的初始化。
// 此时可以通过 super.getPluginJobConf() 获取与本Task相关的配置。
// 这里的配置是 Job 的 split 方法返回的配置列表中的其中一个。
}
public void prepare() {
// 局部的准备工作
}
public void startRead(RecordSender recordSender) {
// 对于 reader 而言是读取数据然后通过 `RecordSender#sendToWriter` 将数据传输到框架中
// 对于 writer 而言是通过 `RecordReceiver#getFromReader` 获取到数据然后写入目的端
}
public void post() {
// 局部的后置工作。
}
public void destroy() {
// Task象自身的销毁工作。
}
}
以及在做插件化的时候有个及其重要的事项,如何解决不同版本相同 Class 的兼容问题
- 比如我想从 MySQL5.7 迁移到 MySQL8.0、HBase0.94 迁移到 HBase2.x 等等这样源端和目的端可能是用了同样 package 下不同 version 的 dependency 怎么处理。
- 源端和目的端由于是不同人开发的,引入了比如 guava-17 和 guava-30 的不同版本是不是会导致程序运行过程中出现
NoSuchMethodError等异常
这时候就需要知道,JVM 中是如何识别 Class 的了,也就是可能面试中常会出现的『双亲委派机制』,我也不知道这个词从哪里派生出来的。只是说 JVM 识别一个 class 会使用到 ClassLoader#loadClass方法,而其中识别这个 ClassName是否被加载过。
- 当前
ClassLoader之前已经加载过这个Class了 - 如果没有加载过,委托父类去完成加载
- 如果不存在父类,则委托
BoostrapClassLoader完成加载 - 若父类加载器无法完成类的加载,当前类加载器才会去尝试加载该类。
也就是说只要能在证明自己已经加载过这些类,就不会存在父类去加载该类的情况,即如果存在两个都叫做 com.A的类文件,如果存在两个 ClassLoader已经认识到自己加载过其中某一个类,实际在一个 JVM 中两个类都分别被加载了(不同版本的共存),只需要在使用该类的时候是从正确的 ClassLoader#loadClass获取到该类即可。即打破了双亲委派。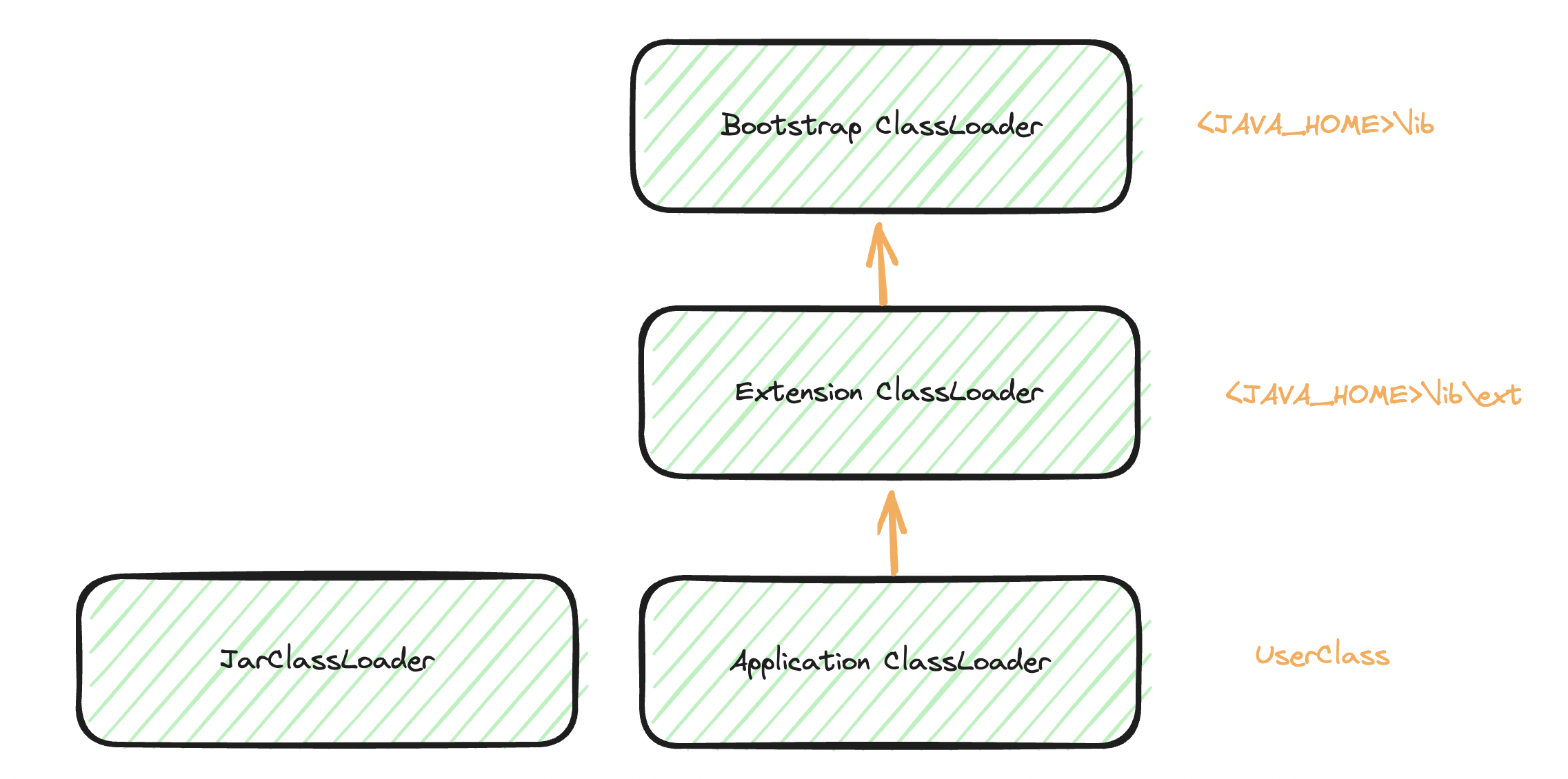
在 DataX 中自己实现了 JarLoader 继承 URLClassLoader通过传入构造器中的 plugin.jar 路径来帮助 findClass 方法能找到 plugin.jar。此时从类加载关系来看 JarLoader 与 ApplicationClassLoader是平行关系,如果需要使用到 Plugin 接口通过在执行的线程中自定义当前类加载器 Thread.currentThread().setContextClassLoader。
可以在 JobContainer 中看到在执行每个 Plugin 接口操作前都会替换线程类加载器。并且在 WriterThread 与 ReaderThread 创建的时候也调用了 setContextClassLoader 方法。
1 | public TaskExecutor(Configuration taskConf, int attemptCount) { |
为了配合 DataX 的 Plugin 框架层做了较大的改动,原则上框架和 Plugin 不会存在变量之间的互相传递,Record 的传递也是以框架通过 Class.newInstance()生成之后填充为准,保证不会出现在变量传递之间出现 Class 不匹配问题(编译不报错运行出错)。
消息流通
消息是通过 Reader 产生通过 Channel 流向 Writer,而消息流通并不仅限于此,而是包含了 Reader 如何产生消息,框架 Record 如何设计以解决不同 Plugin 的数据差异,Writer 又如何将这些消息写入到目的端。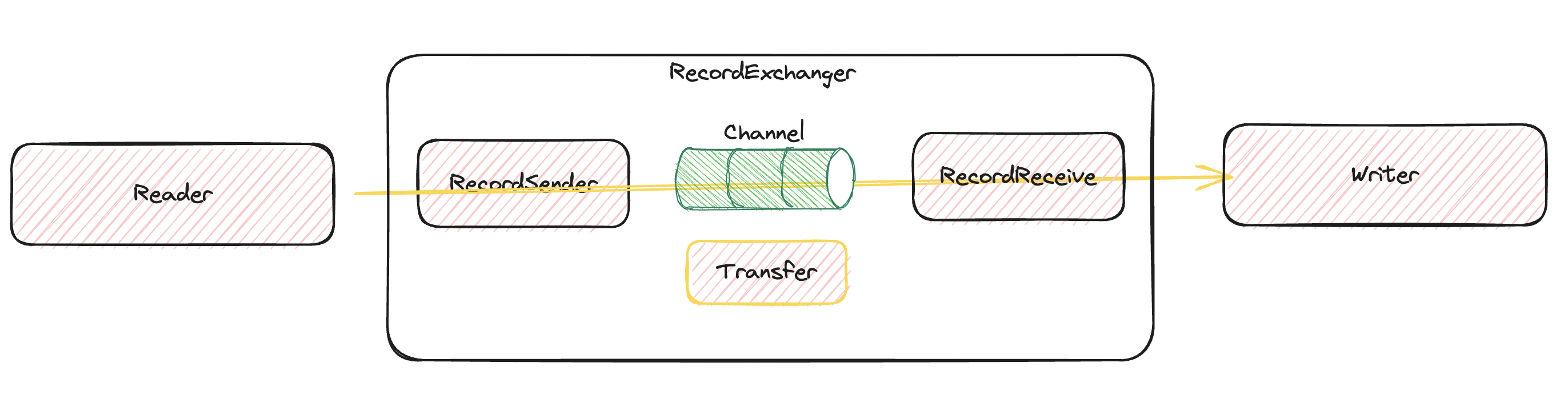
- Reader 产生消息通过接口将 Record 存入 Channel 中,Channel 的存在同时可以作为控制内存、控制全局流量的通道,在 Memory 中是以朴素有用的阻塞队列实现的
- Writer 主动拉取消息让写入攒批频率控制权交给 Writer,方便实现目的端流量监控能力。
要让所有 Plugin 编写简单,统一抽象所有数据源的 Record 是最为重要的工作。
1 | public interface Record { |
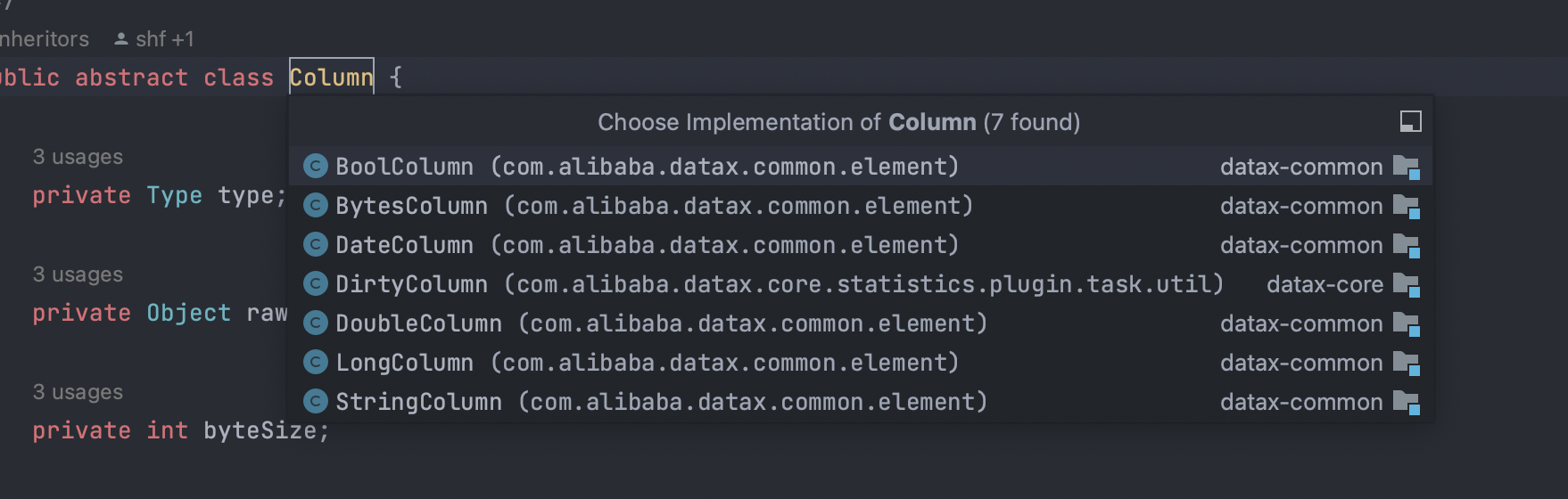
实际实现对应BoolColumn -> BooleanBytesColumn -> byte[]DateColumn -> DateDirtyColumn -> 不实现DoubleColumn -> DoubleLong -> LongStringColumn -> String
在当前 DataX 的设计中必然会因为很多无法用原生类型表示的数据需要 String 来补位。
其他
统计信息
Communication类是 job / taskGroup / task 信息交互,汇报聚集的类。
- 计数器,比如读取的字节速度,写入成功的数据条数
- 统计的时间点 字符串类型的消息
- 执行时的异常
- 执行的状态, 比如成功或失败
分布式架构
DataX 是允许以 TaskGroup 的方式单独运行,而不是仅允许以 Job 的方式全局允许。
这个前提就给了上层实现分布式架构的可行性,当上游调度确定分片任务之后,生成分片配置,完全可以让不同机器/进程运行不同的 Task,在资源上突破单进程带来的瓶颈。
性能压测与性能指标统计
TODO